
Doc2x API v2 PDF 接口文档
基础信息
历史接口
Base URL
https://v2.doc2x.noedgeai.com
重要提醒
- 请直连访问 API 接口,中国内地以外地区可能有较大网络波动,导致上传文件断流严重
- 通过 status 得到结果之后,如果有保存图片的需求,请尽快手动下载或通过导出接口获取图片到本地,服务器上只临时保留 24h 的结果
Authorization 鉴权
首先需要获取到 API Key(类似于 sk-xxx) 获取 API 网址: open.noedgeai.com
在 HTTP 请求头加入:
bash
Authorization: Bearer sk-xxx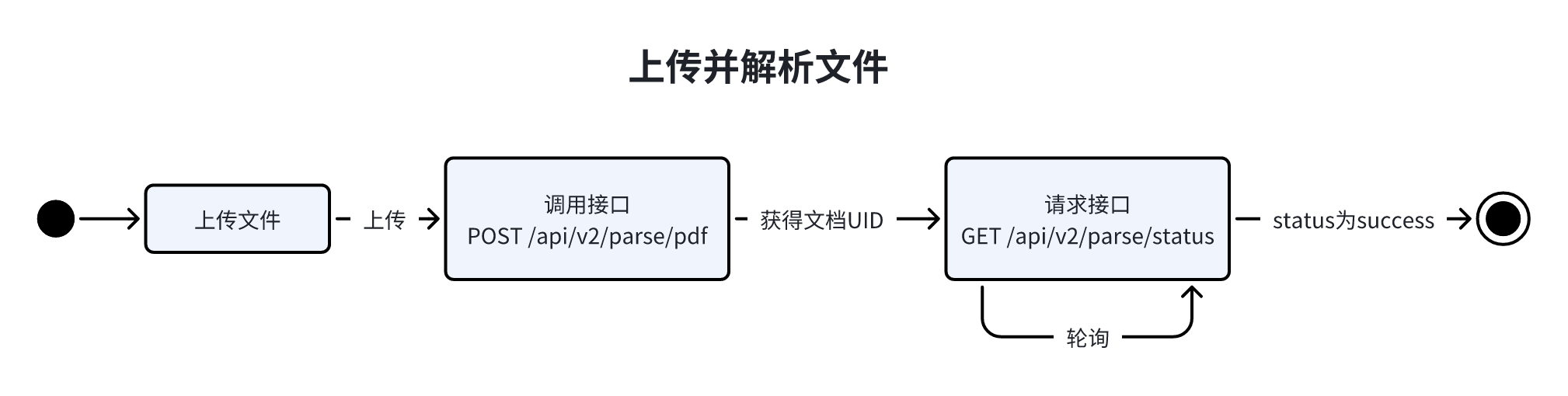
POST /api/v2/parse/preupload 文件预上传
推荐使用该接口,有更快的上传速度
大文件上传接口,文件大小<=1GB
请求参数
model 可选,取值范围:v2、v3-2026 或留空,其余值将返回参数错误。默认不填使用 v2 模型,若想体验最新模型请填写 v3-2026
json
{
"model": "v3-2026"
}请求示例
bash
curl -X POST 'https://v2.doc2x.noedgeai.com/api/v2/parse/preupload' \
--header 'Authorization: Bearer sk-xxx'返回示例
json
{
"code": "success",
"data": {
"uid": "0192d745-5776-7261-abbd-814df3af3449",
"url": "https://doc2x-pdf.oss-cn-beijing.aliyuncs.com/tmp/0192d745-5776-7261-abbd-814df3af3449.pdf?X-Amz-Algorithm=AWS4-HMAC-SHA256..."
}
}- 获取到 url 之后,使用 HTTP PUT 方法上传文件到返回结果中的 url 字段
- 上传完成后,使用
/api/v2/parse/status接口轮询结果,使用的是阿里云的 oss,具体速度取决于您的网速(海外用户速度可能上传失败)。
接口说明
流程图如下:
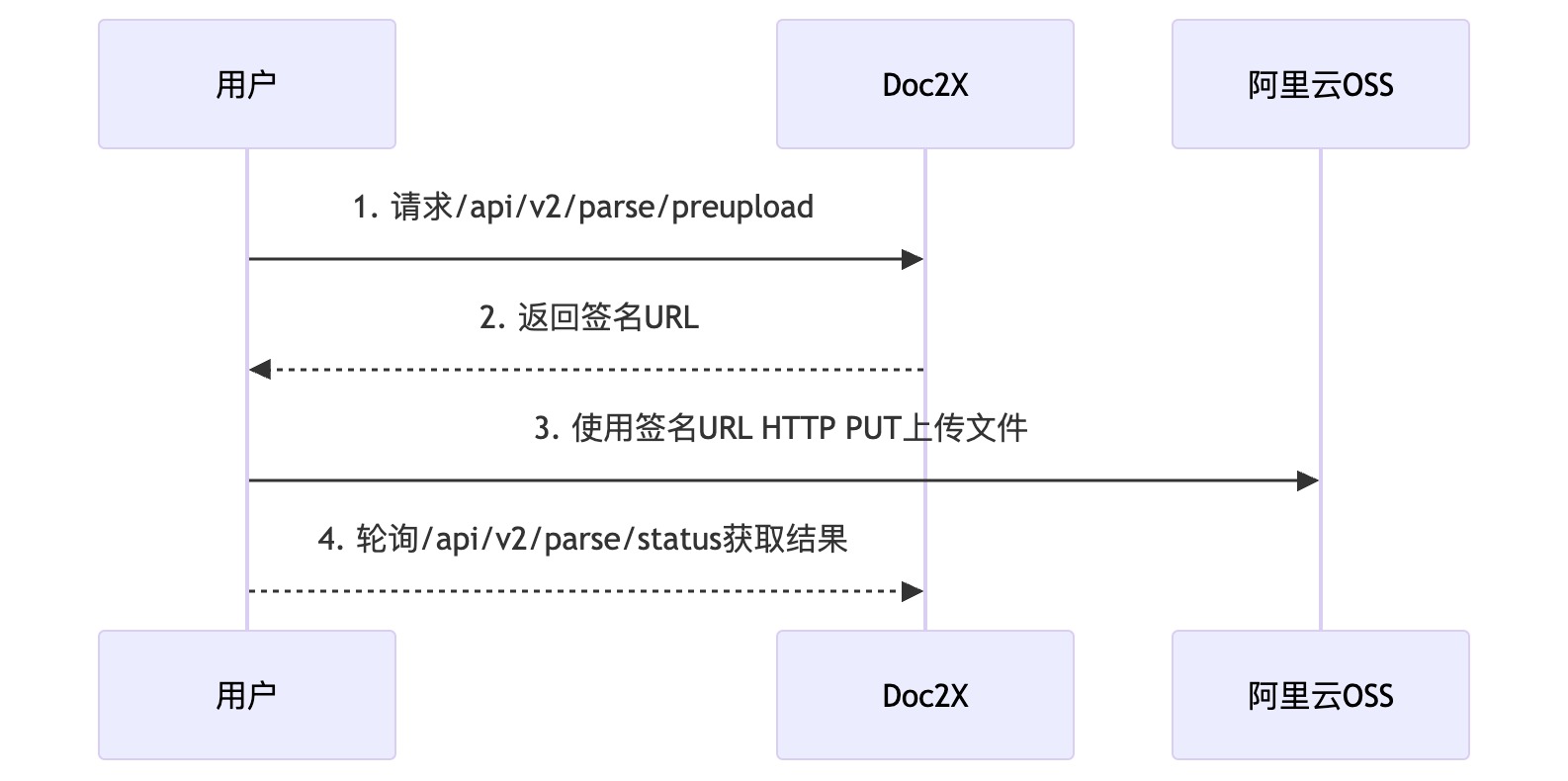
其中异常报错(例如处理进程上限限制/处理页数上限限制)会在 status 接口返回
Python 示例
python
import json
import time
import requests as rq
base_url = "https://v2.doc2x.noedgeai.com"
secret = "sk-xxx"
def preupload():
url = f"{base_url}/api/v2/parse/preupload"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.post(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get preupload url failed: {data}")
else:
raise Exception(f"get preupload url failed: {res.text}")
def put_file(path: str, url: str):
with open(path, "rb") as f:
res = rq.put(url, data=f) # body为文件二进制流
if res.status_code != 200:
raise Exception(f"put file failed: {res.text}")
def get_status(uid: str):
url = f"{base_url}/api/v2/parse/status?uid={uid}"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.get(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get status failed: {data}")
else:
raise Exception(f"get status failed: {res.text}")
upload_data = preupload()
print(upload_data)
url = upload_data["url"]
uid = upload_data["uid"]
put_file("test.pdf", url)
while True:
status_data = get_status(uid)
print(status_data)
if status_data["status"] == "success":
result = status_data["result"]
with open("result.json", "w") as f:
json.dump(result, f)
break
elif status_data["status"] == "failed":
detail = status_data["detail"]
raise Exception(f"parse failed: {detail}")
elif status_data["status"] == "processing":
# processing
progress = status_data["progress"]
print(f"progress: {progress}")
time.sleep(3)注意事项
- 由于用户上传到 OSS 之后,服务端拉取有一定延迟,所以上传文件之后状态不会立刻更新到"任务进行中",需要等待(<20s)
- 获得链接之后 5min 内有效,注意时间
- url 链接不能重复使用:如果 http put 失败(即 status_code!=200)可以重试,put 如果获得 200 返回,链接不能重复使用
- 由于在上传文件前无法知晓页数,触发速率限制 (
parse_concurrency_limit,parse_task_limit_exceeded)的提示仅会在 status 接口中触发
GET /api/v2/parse/status 查看异步状态
使用上方的异步调用后,用这个接口轮询状态,建议轮询频率为 1~3s 每次
云端每个 status(包括 cdn 上的图片)仅在 24h 内可以查询到结果,请尽快导出与保存
查看异步状态请求参数
请求头
| 名称 | 描述 | 示例值 |
|---|---|---|
| Authorization | Api key | Bearer sk-usui9lodl89p7r51suvo0awdawd |
请求体
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| uid | query | string | 是 | 异步任务的 id |
查看异步状态请求示例
bash
curl --request GET 'https://v2.doc2x.noedgeai.com/api/v2/parse/status?uid=01920000-0000-0000-0000-000000000000' \
--header 'Authorization: Bearer sk-xxx'python
import requests
url = 'https://v2.doc2x.noedgeai.com/api/v2/parse/status?uid=01920000-0000-0000-0000-000000000000'
headers = {'Authorization': 'Bearer sk-xxx'}
response = requests.get(url, headers=headers)
print(response.text)查看异步状态返回示例
json
{
"code": "success",
"data": {
"status": "success",
"progress": 100,
"result": {
"pages": [
{
"url": "",
"page_idx": 0,
"page_width": 2334,
"page_height": 1313,
"md": "## Test\n\n",
"score": 89
},
{
"url": "",
"page_idx": 1,
"page_width": 2334,
"page_height": 1313,
"md": "## 测试",
"score": 90
}
]
}
}
}失败的情况
json
{
"code": "parse_error",
"msg": "解析错误"
}字段解释
| 字段 | 含义 | 示例 |
|---|---|---|
| data.progress | 任务进度,0~100 的整数 | 100 |
| data.status | processing,failed,success | 进行中,失败,成功 |
| data.detail | status=failed 时,报错的详细信息 | 解析失败,文件过大 |
| data.result.pages | 结果页列表 | |
| page.url | 本页 url,如果本页存在小图片,则不为空,否则为空 | https://cdn.noedgeai.com/xxx.jpg |
| page.page_idx | 页 id,从 0 开始 | |
| page.page_width/height | 页宽/高,单位:像素点 | |
| page.md | 本页的 markdown 格式文本 | |
| page.score | 本页解析质量分(0~100) | 89 |
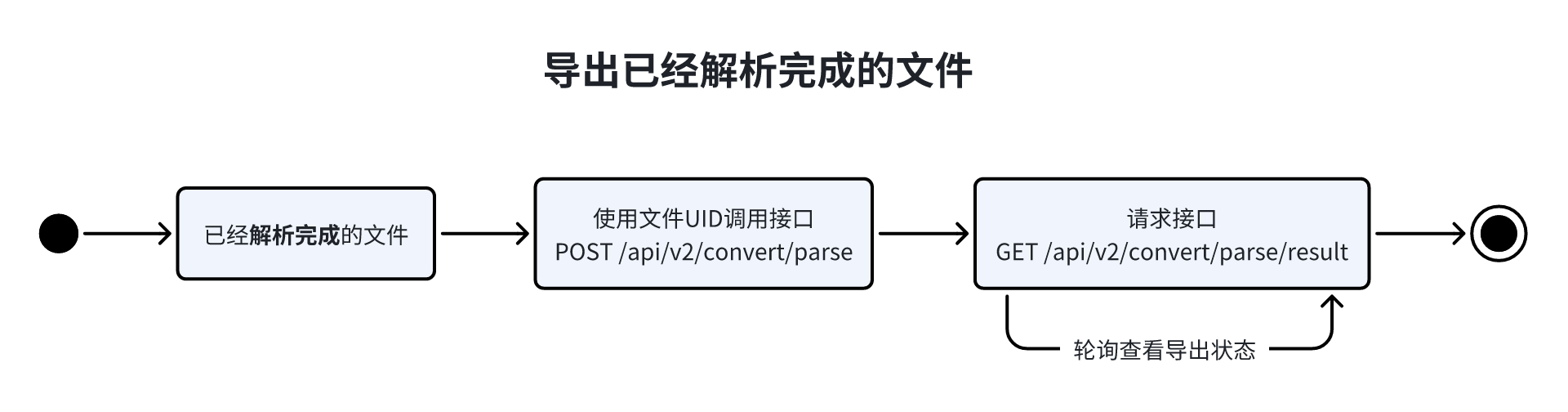
POST /api/v2/convert/parse 请求导出文件(异步)
导出文件请求参数
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| uid | body | json | 是 | 解析任务的 id |
| to | body | json | 是 | 导出格式,支持:md|tex|docx |
| formula_mode | body | json | 是 | 导出模型,需填写:normal;当需要导出使用$标记公式的 md 文件时改为:dollar |
| filename | body | json | 否 | 导出后的 md/tex 文件名(不含后缀名),默认 output.md/output.tex,仅对 md 和 tex 有效 |
| merge_cross_page_forms | body | bool | 否 | 合并跨页表格 |
| formula_level | body | int32 | 否 | 控制公式降级等级,取值 0、1、2,默认 0。仅在使用 v3-2026 模型时生效,v2 模型下该参数无效。0:不退化公式(保留原始 Markdown);1:行内公式变为普通文本(退化 \(...\) 和 $...$);2:全部公式变为普通文本(退化 \(...\) 和 $...$ 和 \[...\] 和 $$...$$) |
导出文件请求示例
bash
curl --location --request POST 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse' \
--header 'Authorization: Bearer sk-xxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"uid": "01920000-0000-0000-0000-000000000000",
"to": "md",
"formula_mode": "normal",
"filename": "my_markdown.md",
"merge_cross_page_forms": false,
"formula_level": 0
}'python
import requests
import json
url = "https://v2.doc2x.noedgeai.com/api/v2/convert/parse"
headers = {
"Authorization": "Bearer sk-xxx",
"Content-Type": "application/json",
}
data = {
"uid": "01920000-0000-0000-0000-000000000000",
"to": "md",
"formula_mode": "normal",
"filename": "my_markdown.md",
"formula_level": 0,
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)导出文件返回示例
json
{
"code": "success",
"data": {
"status": "processing",
"url": ""
}
}注意:接口 /api/v2/convert/parse 用于触发导出文件任务,后续需使用 /api/v2/convert/parse/result 接口轮询导出任务状态,请不要反复轮询 /convert/parse 接口
GET /api/v2/convert/parse/result 导出获取结果
导出获取结果请求参数
导出获取结果请求头
| 名称 | 描述 | 示例值 |
|---|---|---|
| Authorization | Api key | Bearer sk-usui9lodl89p7r51suvo0awdawd |
导出获取结果请求体
| 名称 | 位置 | 类型 | 必选 | 说明 |
|---|---|---|---|---|
| uid | query | string | 是 | 异步任务的 id |
导出获取结果请求示例
bash
curl --location --request GET 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse/result?uid=01920000-0000-0000-0000-000000000000' \
--header 'Authorization: Bearer sk-xxx'python
import requests
url = 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse/result?uid=01920000-0000-0000-0000-000000000000'
headers = {'Authorization': 'Bearer sk-xxx'}
response = requests.get(url, headers=headers)
print(response.text)导出获取结果返回示例
json
{
"code": "success",
"data": {
"status": "success",
"url": "https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?..."
}
}与 /api/v2/convert/parse 导出文件返回结果相同,随后您需要使用其中的 URL 下载文件
从 URL 下载文件
从/api/v2/convert/parse/result或/api/v2/convert/parse接口获得成功返回示例后,您可以使用 HTTP GET 方法请求 url 来下载文件:
注意:部分场景下返回的 url 里面会把&用\u0026 表示,需要主动替换为&
从 URL 下载文件请求示例
bash
curl -L -o downloaded_file.zip "https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?..."python
import requests
response = requests.get("https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?...")
with open('downloaded_file.zip', 'wb') as f:
f.write(response.content)错误码
HTTP 状态码
- 对应 httpcode 为 429 时,为超出 API 速率限制错误,等待先前提交的任务完成
- 对应 httpcode 均为 200,属于业务相关错误
错误代码说明
| 错误代码 | 原因 | 解决方案 |
|---|---|---|
| parse_task_limit_exceeded | 任务数超限制 | 正在处理的任务数量达到上限,等待先前提交的任务完成 |
| parse_concurrency_limit | 任务文件页数超限 | 正在处理的任务页数达到上限,等候先前提交的任务完成 |
| parse_quota_limit | 可用的解析页数额度不足 | 当前可用的页数不够 |
| parse_error | 解析错误 | 短暂等待后重试,如果还出现报错则请联系负责人 |
| parse_create_task_error | 创建任务失败 | 短暂等待后重试,如果还出现报错则请联系负责人 |
| parse_status_not_found | 状态过期或 uid 错误 | 短暂等待后重试,如果还出现报错则请联系负责人 |
| parse_file_too_large | 单个文件大小超过限制 | 当前允许单个文件大小 <= 300M,请拆分 pdf |
| parse_page_limit_exceeded | 单个文件页数超过限制 | 当前允许单个文件页数 <= 2000 页,请拆分 pdf |
| parse_file_lock | 文件解析失败 | 为了防止反复解析,暂时锁定一天。考虑 PDF 可能有兼容性问题,重新打印后再尝试。仍然失败请反馈 request_id 给负责人 |
| parse_file_not_pdf | 传入的文件不是 PDF 文件 | 请解析后缀为.pdf 的文件 |
| parse_file_invalid | 解析文件错误或者不合法 | 我们无法解析这个 pdf,一般是 pdf 格式有问题或者 pdf 不规范 |
| parse_timeout | 处理时间超过 15min | 一般为内容过长导致的 15min 无法全部处理完,尝试切分 pdf 再识别 |