
Doc2X API v2 PDF Interface Documentation
Basic Information
Legacy Endpoints
End of Maintenance
POST /api/v2/parse/pdf will be discontinued in a future release. New integrations are not recommended.
We recommend migrating to POST /api/v2/parse/preupload.
Base URL
https://v2.doc2x.noedgeai.com
Important Reminders
- Please access the API interface directly. Regions outside mainland China may experience significant network fluctuations, leading to severe file upload interruptions
- After obtaining results through status, if you need to save images, please download manually or obtain images locally through the export interface as soon as possible. The server only temporarily retains results for 24 hours
Authorization
First, you need to obtain an API Key (similar to sk-xxx). Get API website: open.noedgeai.com
Add to HTTP request headers:
Authorization: Bearer sk-xxx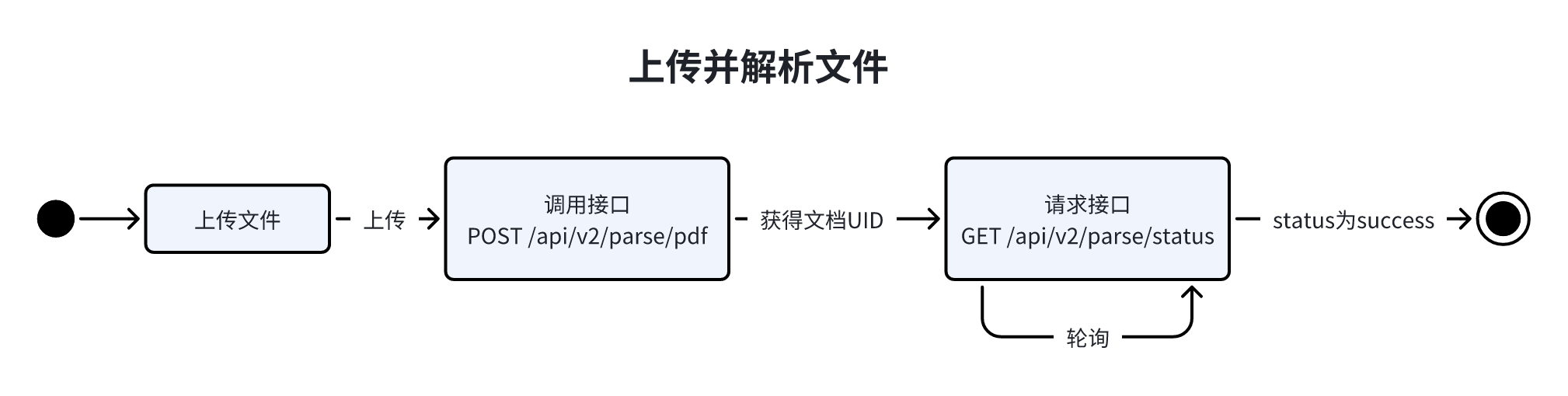
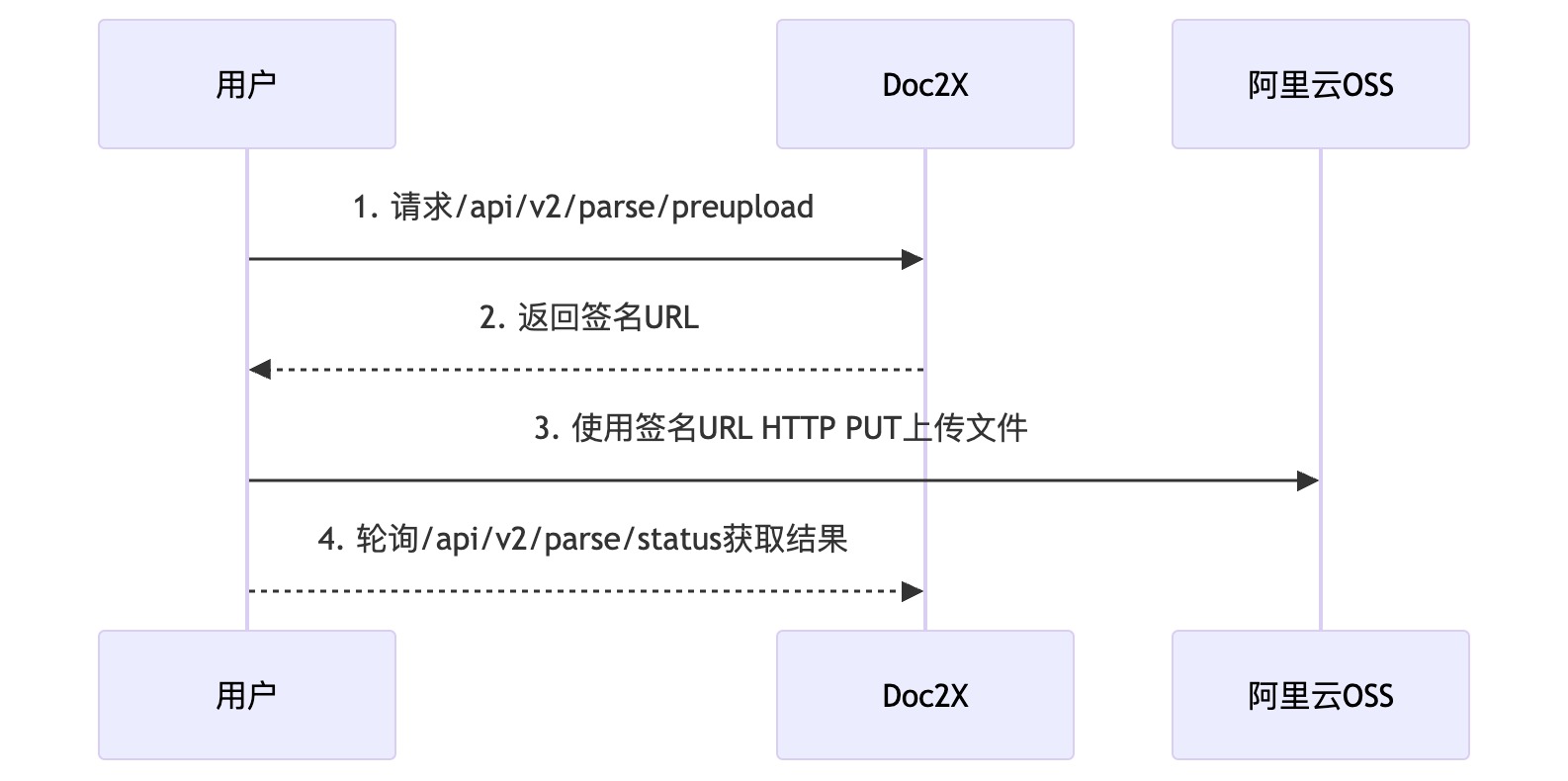
POST /api/v2/parse/preupload File Pre-upload
Recommended to use this interface for faster upload speeds
Large file upload interface, file size <= 1GB
Request Parameters
model(optional): accepted values are v2, v3-2026, or empty. Any other value will return a parameter error. Default model is v2, can be set to v3-2026 to use the latest model
{
"model": "v3-2026"
}Request Example
curl -X POST 'https://v2.doc2x.noedgeai.com/api/v2/parse/preupload' \
--header 'Authorization: Bearer sk-xxx'Response Example
{
"code": "success",
"data": {
"uid": "0192d745-5776-7261-abbd-814df3af3449",
"url": "https://doc2x-pdf.oss-cn-beijing.aliyuncs.com/tmp/0192d745-5776-7261-abbd-814df3af3449.pdf?X-Amz-Algorithm=AWS4-HMAC-SHA256..."
}
}- After obtaining the url, use HTTP PUT method to upload the file to the url field in the returned result
- After upload completion, use the
/api/v2/parse/statusinterface to poll for results. Uses Alibaba Cloud OSS, specific speed depends on your network speed (overseas users may experience upload failures).
Interface Description
Flow chart as follows:
Exception errors (such as processing limit/processing page limit restrictions) will be returned in the status interface
Python Example
import json
import time
import requests as rq
base_url = "https://v2.doc2x.noedgeai.com"
secret = "sk-xxx"
def preupload():
url = f"{base_url}/api/v2/parse/preupload"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.post(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get preupload url failed: {data}")
else:
raise Exception(f"get preupload url failed: {res.text}")
def put_file(path: str, url: str):
with open(path, "rb") as f:
res = rq.put(url, data=f) # body is file binary stream
if res.status_code != 200:
raise Exception(f"put file failed: {res.text}")
def get_status(uid: str):
url = f"{base_url}/api/v2/parse/status?uid={uid}"
headers = {
"Authorization": f"Bearer {secret}"
}
res = rq.get(url, headers=headers)
if res.status_code == 200:
data = res.json()
if data["code"] == "success":
return data["data"]
else:
raise Exception(f"get status failed: {data}")
else:
raise Exception(f"get status failed: {res.text}")
upload_data = preupload()
print(upload_data)
url = upload_data["url"]
uid = upload_data["uid"]
put_file("test.pdf", url)
while True:
status_data = get_status(uid)
print(status_data)
if status_data["status"] == "success":
result = status_data["result"]
with open("result.json", "w") as f:
json.dump(result, f)
break
elif status_data["status"] == "failed":
detail = status_data["detail"]
raise Exception(f"parse failed: {detail}")
elif status_data["status"] == "processing":
# processing
progress = status_data["progress"]
print(f"progress: {progress}")
time.sleep(3)Notes
- Since there is a certain delay for the server to fetch after users upload to OSS, the status will not immediately update to "task in progress" after uploading files, you need to wait (<20s)
- The link is valid for 5 minutes after obtaining it, pay attention to timing
- URL links cannot be reused: if HTTP PUT fails (i.e., status_code!=200), you can retry. If PUT gets a 200 return, the link cannot be reused
- Since the number of pages cannot be known before uploading the file, rate limit triggers (
parse_concurrency_limit,parse_task_limit_exceeded) will only be triggered in the status interface
GET /api/v2/parse/status View Asynchronous Status
After using the above asynchronous call, use this interface to poll status. Recommended polling frequency is 1~3 seconds per time
Cloud status (including images on CDN) can only be queried for results within 24 hours. Please export and save as soon as possible
View Asynchronous Status Request Parameters
Request Headers
| Name | Description | Example Value |
|---|---|---|
| Authorization | Api key | Bearer sk-usui9lodl89p7r51suvo0awdawd |
Request Body
| Name | Location | Type | Required | Description |
|---|---|---|---|---|
| uid | query | string | Yes | Asynchronous task id |
View Asynchronous Status Request Example
curl --request GET 'https://v2.doc2x.noedgeai.com/api/v2/parse/status?uid=01920000-0000-0000-0000-000000000000' \
--header 'Authorization: Bearer sk-xxx'import requests
url = 'https://v2.doc2x.noedgeai.com/api/v2/parse/status?uid=01920000-0000-0000-0000-000000000000'
headers = {'Authorization': 'Bearer sk-xxx'}
response = requests.get(url, headers=headers)
print(response.text)View Asynchronous Status Response Example
{
"code": "success",
"data": {
"status": "success",
"progress": 100,
"result": {
"pages": [
{
"url": "",
"page_idx": 0,
"page_width": 2334,
"page_height": 1313,
"md": "## Test\n\n",
"score": 89
},
{
"url": "",
"page_idx": 1,
"page_width": 2334,
"page_height": 1313,
"md": "## 测试",
"score": 90
}
]
}
}
}Failed Case
{
"code": "parse_error",
"msg": "Parse error"
}Field Explanations
| Field | Meaning | Example |
|---|---|---|
| data.progress | Task progress, integer from 0~100 | 100 |
| data.status | processing, failed, success | In progress, failed, success |
| data.detail | Detailed error information when status=failed | Parse failed, file too large |
| data.result.pages | Result pages | |
| page.url | Page URL, not empty if small images exist on page, otherwise empty | https://cdn.noedgeai.com/xxx.jpg |
| page.page_idx | Page id, starting from 0 | |
| page.page_width/height | Page width/height, unit: pixels | |
| page.md | Markdown format text for this page | |
| page.score | Parse quality score for this page (0~100) | 89 |
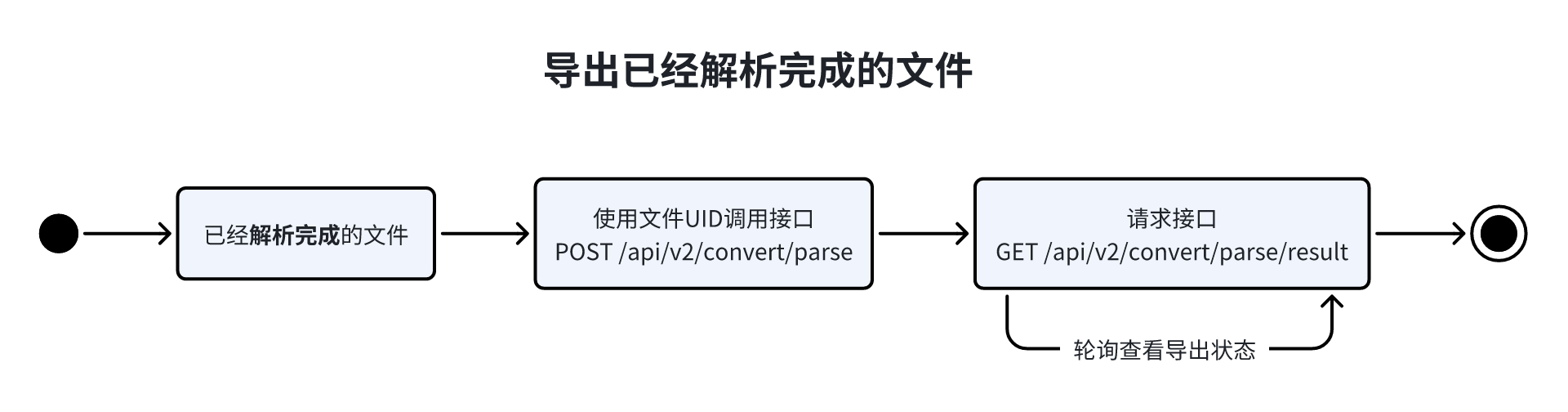
POST /api/v2/convert/parse Request Export File (Asynchronous)
Export File Request Parameters
| Name | Location | Type | Required | Description |
|---|---|---|---|---|
| uid | body | json | Yes | Parse task id |
| to | body | json | Yes | Export format, supports: md|tex|docx |
| formula_mode | body | json | Yes | Export mode, fill in: normal; change to: dollar when exporting md files with $ formula markers |
| filename | body | json | No | Exported md/tex filename (without extension), default output.md/output.tex, only valid for md and tex |
| merge_cross_page_forms | body | bool | No | Merge cross-page tables |
| formula_level | body | int32 | No | Controls formula degradation level, values 0, 1, 2, default 0. Only effective when using the v3-2026 model, this parameter has no effect under the v2 model. 0: No formula degradation (keep original Markdown); 1: Inline formulas become plain text (degrades \(...\) and $...$); 2: All formulas become plain text (degrades \(...\) and $...$ and \[...\] and $$...$$) |
Export File Request Example
curl --location --request POST 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse' \
--header 'Authorization: Bearer sk-xxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"uid": "01920000-0000-0000-0000-000000000000",
"to": "md",
"formula_mode": "normal",
"filename": "my_markdown.md",
"merge_cross_page_forms": false,
"formula_level": 0
}'import requests
import json
url = "https://v2.doc2x.noedgeai.com/api/v2/convert/parse"
headers = {
"Authorization": "Bearer sk-xxx",
"Content-Type": "application/json",
}
data = {
"uid": "01920000-0000-0000-0000-000000000000",
"to": "md",
"formula_mode": "normal",
"filename": "my_markdown.md",
"formula_level": 0,
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)Export File Response Example
{
"code": "success",
"data": {
"status": "processing",
"url": ""
}
}Note: The interface /api/v2/convert/parse is used to trigger export file tasks. Subsequently, you need to use the /api/v2/convert/parse/result interface to poll export task status. Do not repeatedly poll the /convert/parse interface
GET /api/v2/convert/parse/result Export Get Results
Export Get Results Request Parameters
Export Get Results Request Headers
| Name | Description | Example Value |
|---|---|---|
| Authorization | Api key | Bearer sk-usui9lodl89p7r51suvo0awdawd |
Export Get Results Request Body
| Name | Location | Type | Required | Description |
|---|---|---|---|---|
| uid | query | string | Yes | Asynchronous task id |
Export Get Results Request Example
curl --location --request GET 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse/result?uid=01920000-0000-0000-0000-000000000000' \
--header 'Authorization: Bearer sk-xxx'import requests
url = 'https://v2.doc2x.noedgeai.com/api/v2/convert/parse/result?uid=01920000-0000-0000-0000-000000000000'
headers = {'Authorization': 'Bearer sk-xxx'}
response = requests.get(url, headers=headers)
print(response.text)Export Get Results Response Example
{
"code": "success",
"data": {
"status": "success",
"url": "https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?..."
}
}Same as /api/v2/convert/parse export file return results, then you need to use the URL in it to download the file
Download File from URL
After getting successful return examples from /api/v2/convert/parse/result or /api/v2/convert/parse interfaces, you can use HTTP GET method to request the url to download the file:
Note: In some scenarios, the returned url will represent & with \u0026, which needs to be actively replaced with &
Download File from URL Request Example
curl -L -o downloaded_file.zip "https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?..."import requests
response = requests.get("https://doc2x-backend.s3.cn-north-1.amazonaws.com.cn/objects/xxx/convert_tex_none.zip?...")
with open('downloaded_file.zip', 'wb') as f:
f.write(response.content)Error Codes
HTTP Status Codes
- When httpcode is 429, it's an API rate limit exceeded error, wait for previously submitted tasks to complete
- When httpcode is 200, it's a business-related error
Error Code Descriptions
| Error Code | Reason | Solution |
|---|---|---|
| parse_task_limit_exceeded | Task number limit exceeded | Number of tasks being processed has reached the limit, wait for previously submitted tasks to complete |
| parse_concurrency_limit | Task file page limit exceeded | Pages being processed have reached the limit, wait for previously submitted tasks to complete |
| parse_quota_limit | Insufficient parsing page quota | Current available pages are insufficient |
| parse_error | Parse error | Wait briefly and retry, if error persists contact the person in charge |
| parse_create_task_error | Task creation failed | Wait briefly and retry, if error persists contact the person in charge |
| parse_status_not_found | Status expired or uid error | Wait briefly and retry, if error persists contact the person in charge |
| parse_file_too_large | Single file size exceeds limit | Currently allows single file size <= 300M, please split PDF |
| parse_page_limit_exceeded | Single file page count exceeds limit | Currently allows single file pages <= 2000 pages, please split PDF |
| parse_file_lock | File parsing failed | To prevent repeated parsing, temporarily locked for one day. Consider PDF compatibility issues, try reprinting and try again. If still fails, feedback request_id to person in charge |
| parse_file_not_pdf | Uploaded file is not a PDF | Please parse files with .pdf extension |
| parse_file_invalid | Parse file error or invalid | We cannot parse this PDF, usually PDF format issues or non-standard PDF |
| parse_timeout | Processing time exceeds 15min | Usually caused by content being too long to process completely within 15min, try splitting PDF for recognition |
Useful Integrations
Packaged Python Library - pdfdeal
- Source code: https://github.com/NoEdgeAI/pdfdeal-docs
- Documentation: https://noedgeai.github.io/pdfdeal-docs/zh/guide/
Coze Plugin - PDF Recognition from URL
- Plugin address: https://www.coze.cn/store/plugin/7398010704374153253