Parsing Features Introduction
Basic Functions
- Parse text/tables/formulas/layout from PDFs and restore them to Markdown, LaTeX, and Word formats (Word does not include layout restoration)
- Use cases: Provide higher quality data for large language model training and RAG
- Core scenarios: Including but not limited to Chinese/English papers, financial reports/annual reports, middle school science test papers, various books, etc.
Features
Remove Headers and Footers from PDFs
- Such as page numbers, journal names, authors that repeatedly appear at the top/bottom of paper pages
Universal Table Recognition
- Recognizes tables in HTML format (markdown tables don't support merged cell syntax)
- No specific table type limitations, performs well in general scenarios
- Supports recognition of rotated tables on pages (both left and right rotated tables)
- Supports recognition of formulas/images/paragraphs within tables
- Supports merging of cross-page tables, removing continuation table text, merging cross-page cells and removing duplicate headers
- Does not support recognition of nested tables
Formula Recognition
- Supports mixed text and formula recognition as well as Chinese formula recognition
- Supports most formulas except extremely large equation systems and matrices
Layout Restoration
- Restores complex layout documents to single-column text flow
- Supports most layouts except newspaper-style multi-column layouts
- Currently supporting multi-level headings (h1-h5)
- Partial support for code block indentation
Supported Languages
- Supported languages: Chinese (Simplified/Traditional), English, Western European languages, Japanese
- Future support planned: Russian, Hindi, Arabic
Handwriting Recognition
- Handwritten text/formula recognition is continuously supported
Parsing Tutorial
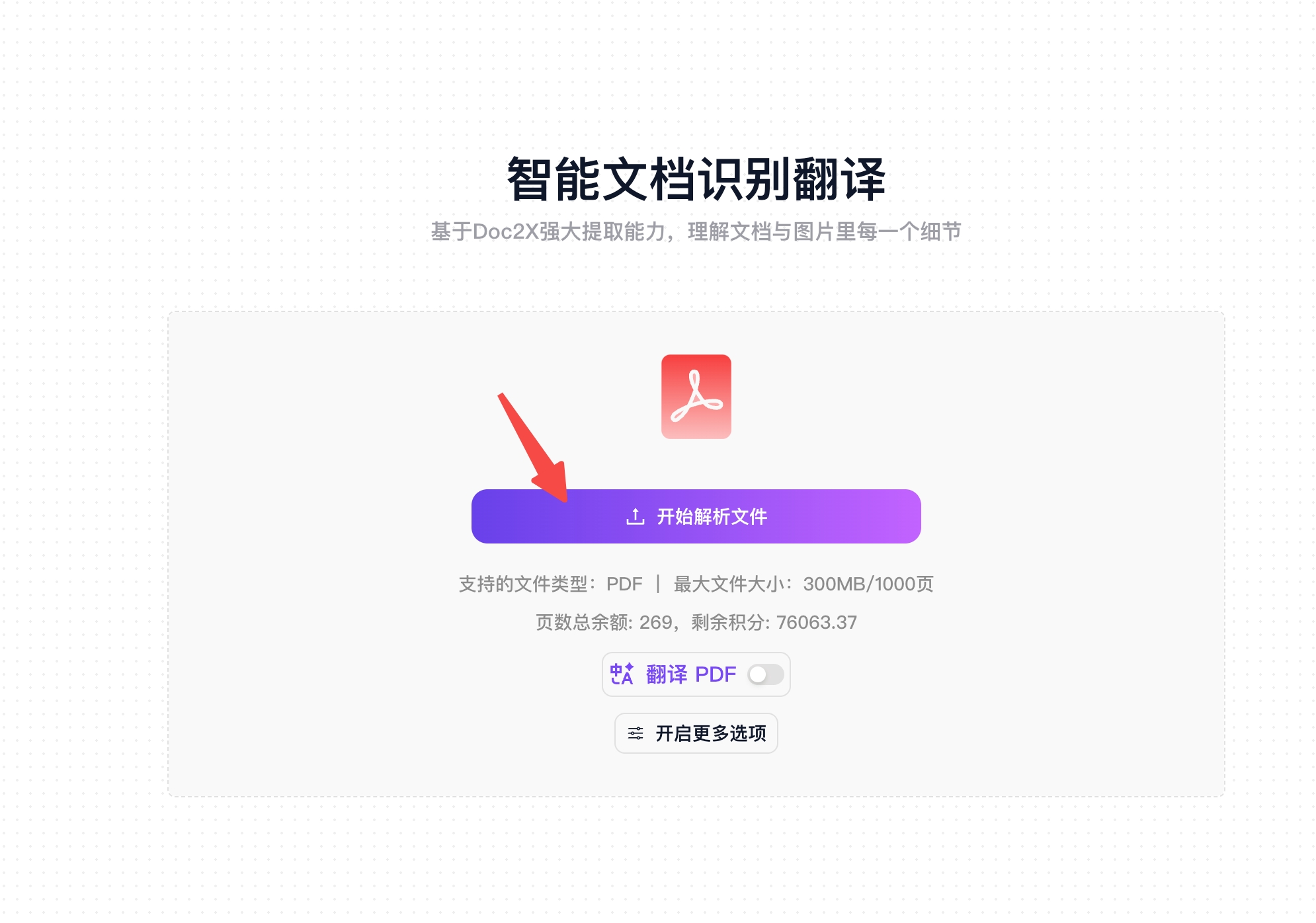
Step 1: Upload Document
- Click the "Start Parsing File" button or directly drag and drop PDF files to the upload area
- Supports single file upload, maximum 300MB PDF documents supported
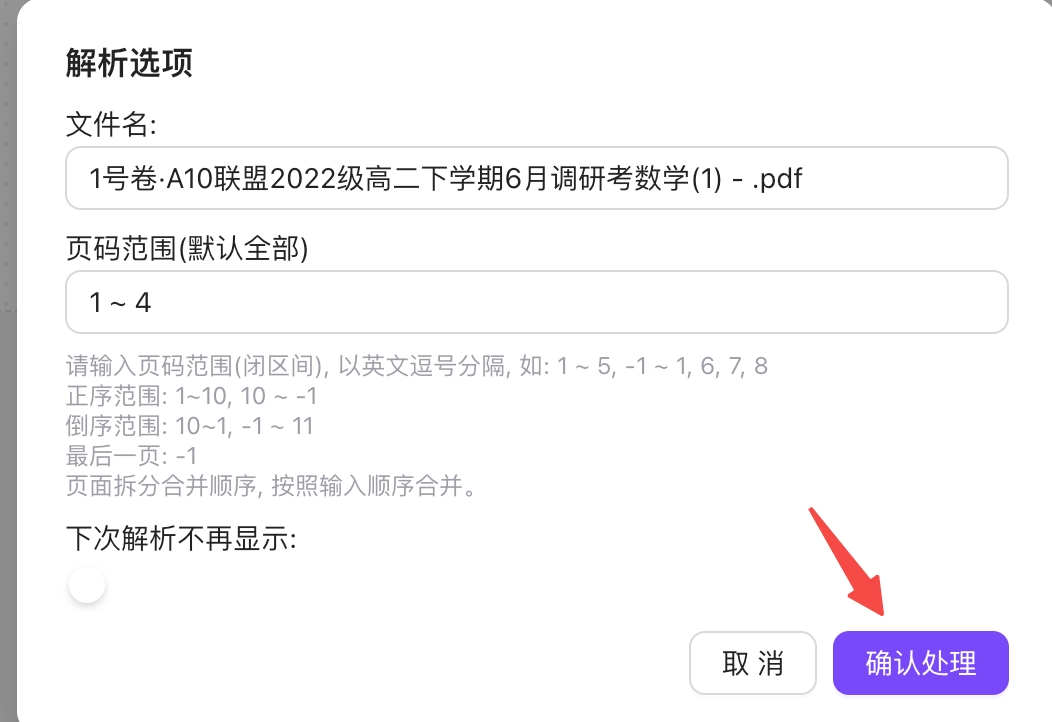
Step 2: Start Parsing
- Page Range: Select the page range to parse (All/Specific pages/Specific range)
- No parsing model needs to be selected. The system uses the recommended parsing capability by default and automatically applies the current parsing discount
- Click the "Confirm Processing" button, system begins processing the document
- Processing progress is displayed in real-time
- After parsing is complete, you can preview results and download files
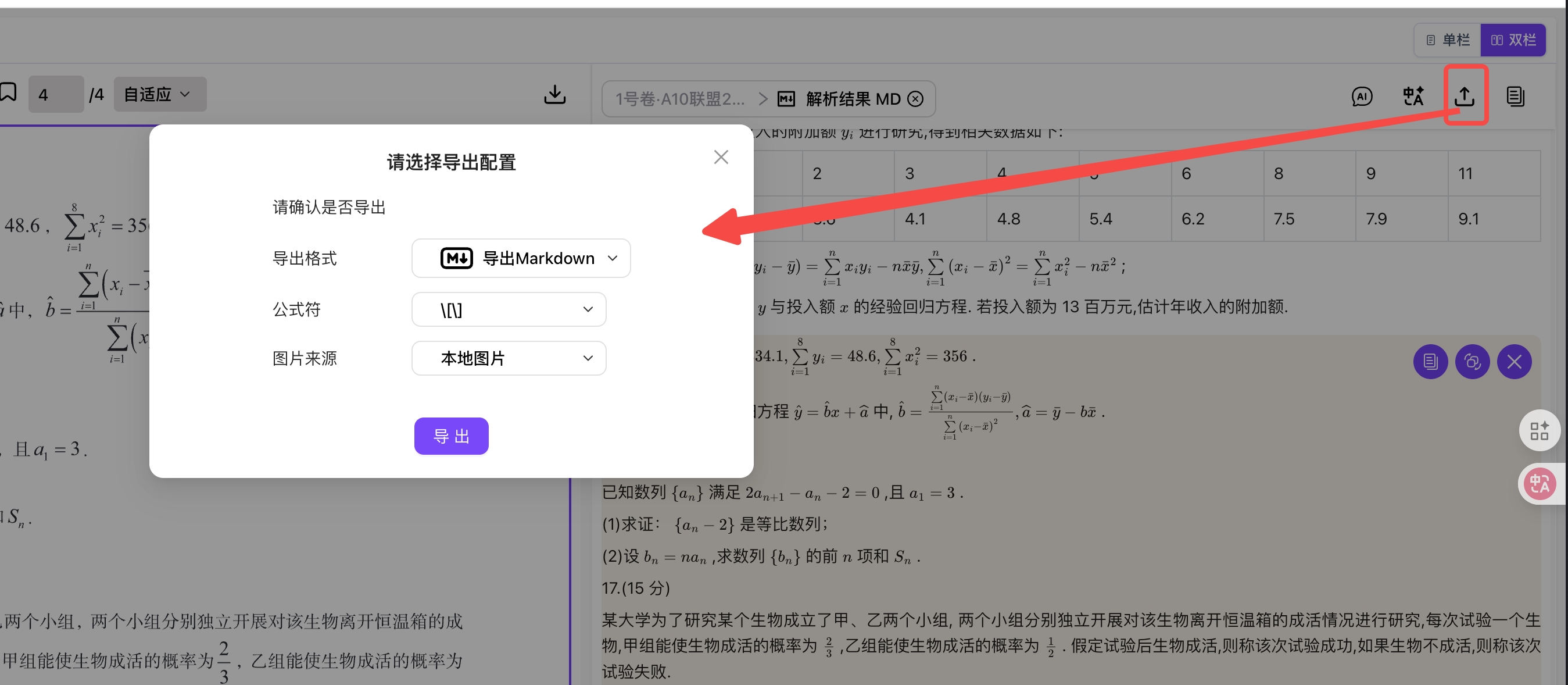
Step 3: Preview Parsing Results
- Parsing Results: View document elements identified by the system, such as titles, paragraphs, tables, images, etc.
- Operation Menu:
- Copy parsing results as Markdown
- Export as Markdown, Word, and other formats
- Single-column/double-column toggle
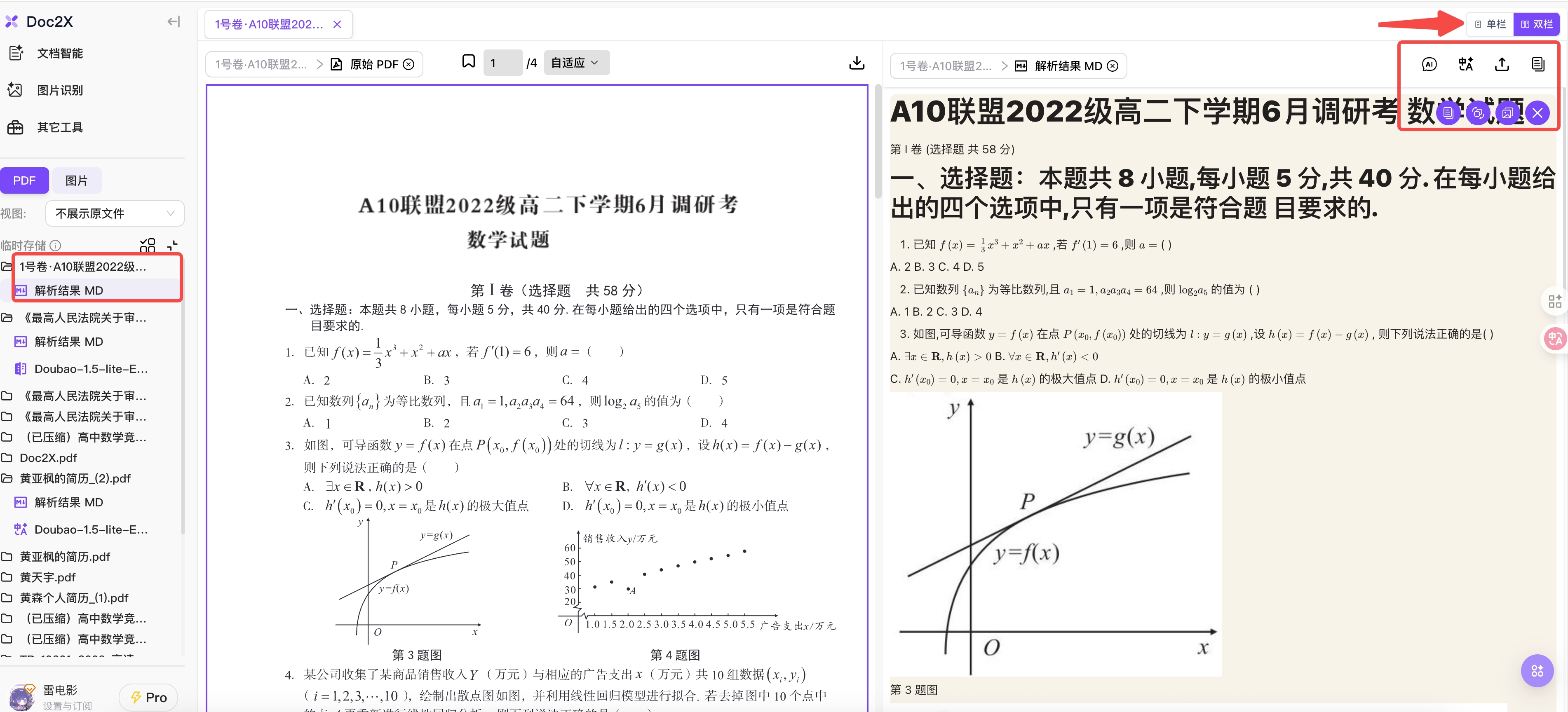
Step 4: Download Parsing Results
- Click the "Export" icon, select the file format to save (Markdown, Word, etc.)
- You can then save the parsing results locally