解析功能介绍
基本功能
- 解析 PDF 里面的文字/表格/公式/表格/排版 还原成 Markdown、LaTeX和Word(Word不包含排版还原)
- 适用场景:为大语言模型训练与 RAG 提供更优质的数据
- 核心场景:包括但不限于 中英论文/财报年报/中学理科试卷/各种书籍等
特点
去除 PDF 中的页眉页脚
- 例如页码、论文页上方/下方反复出现的期刊名、作者
通用表格识别
- 识别成 HTML 格式的表格(markdown 表格不支持合并单元格的语法)
- 没有特定局限的表格种类,通用场景表现较好
- 支持页面中的旋转表格的识别(左旋右旋表格均支持)
- 支持表格内的公式/图像/段落的识别
- 支持跨页表格的合并,支持去除续表相关文字,合并跨页单元格和去除重复表头
- 不支持表中表的识别
公式识别
- 支持文字和公式混排识别以及中文公式的识别
- 除了超大的方程组与矩阵均支持较好
布局还原
- 将复杂版面文档还原成单栏文字流
- 除了报纸类的超多栏外基本都支持
- 正在支持多级标题(h1-h5)
- 部分支持代码块的缩进支持
支持语言
- 支持语言:中文(简体/繁体)、英语、西欧各国语言、日语
- 未来预计支持:俄语、印度语、阿拉伯语
手写识别
- 手写文字/公式持续支持中
解析操作教程
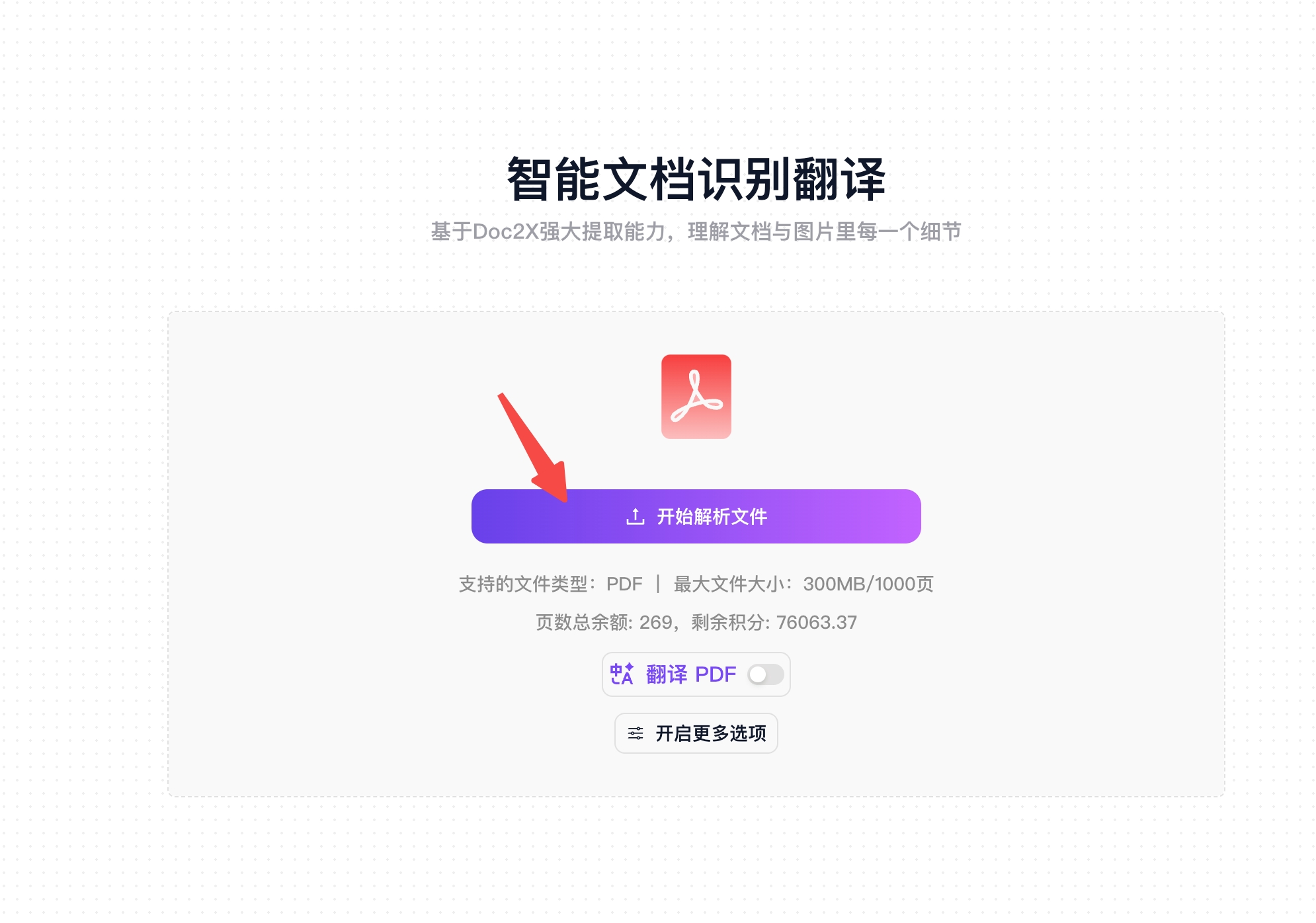
步骤 1:上传文档
- 点击"开始解析文件"按钮或直接拖拽 PDF 文件到上传区域
- 支持单个文件上传,最大支持 300MB 的 PDF 文档
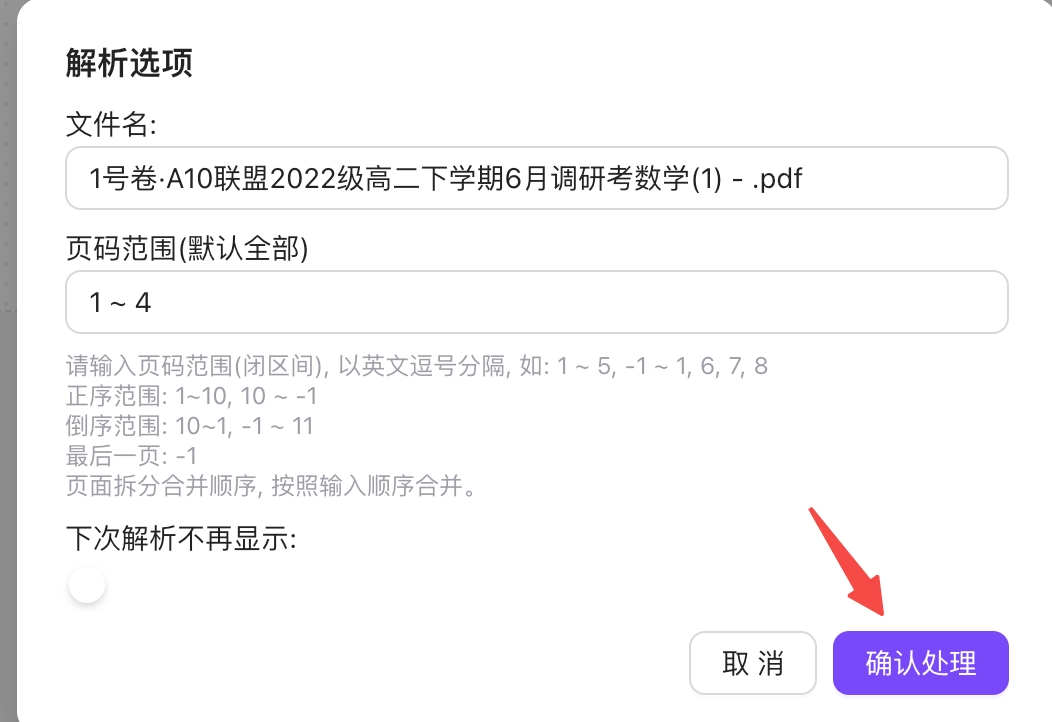
步骤 2:开始解析
- 解析页码:选择要解析的页码范围(全部/指定页码/指定范围)
- 解析无需选择模型,系统默认使用推荐解析能力,并会自动应用当前解析折扣
- 点击"确认处理"按钮,系统开始处理文档
- 处理进度会实时显示
- 解析完成后可预览结果并下载文件
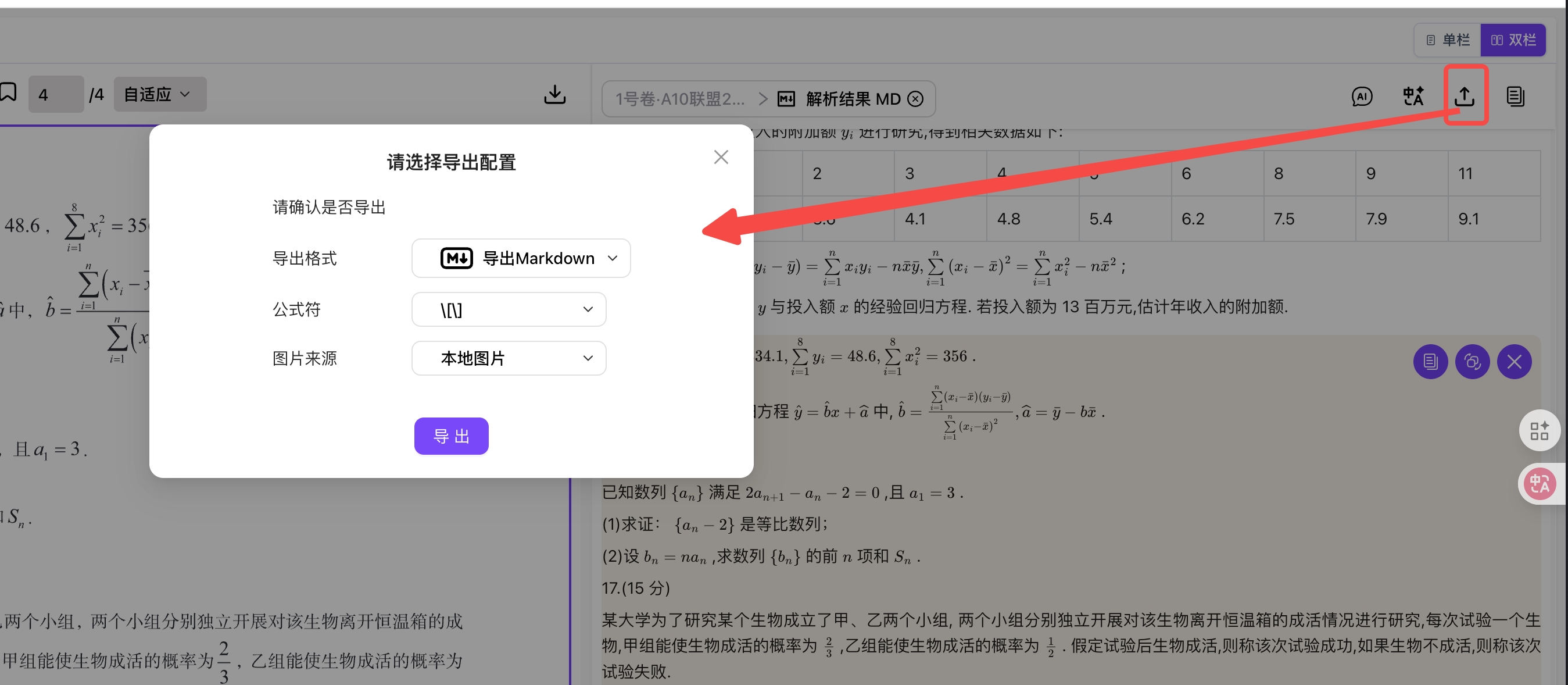
步骤 3:预览解析结果
- 解析结果:查看系统识别出的文档元素,如标题、段落、表格、图片等
- 操作菜单:
- 复制解析结果为 Markdown
- 导出为 Markdown、Word 等格式
- 单栏/双栏切换
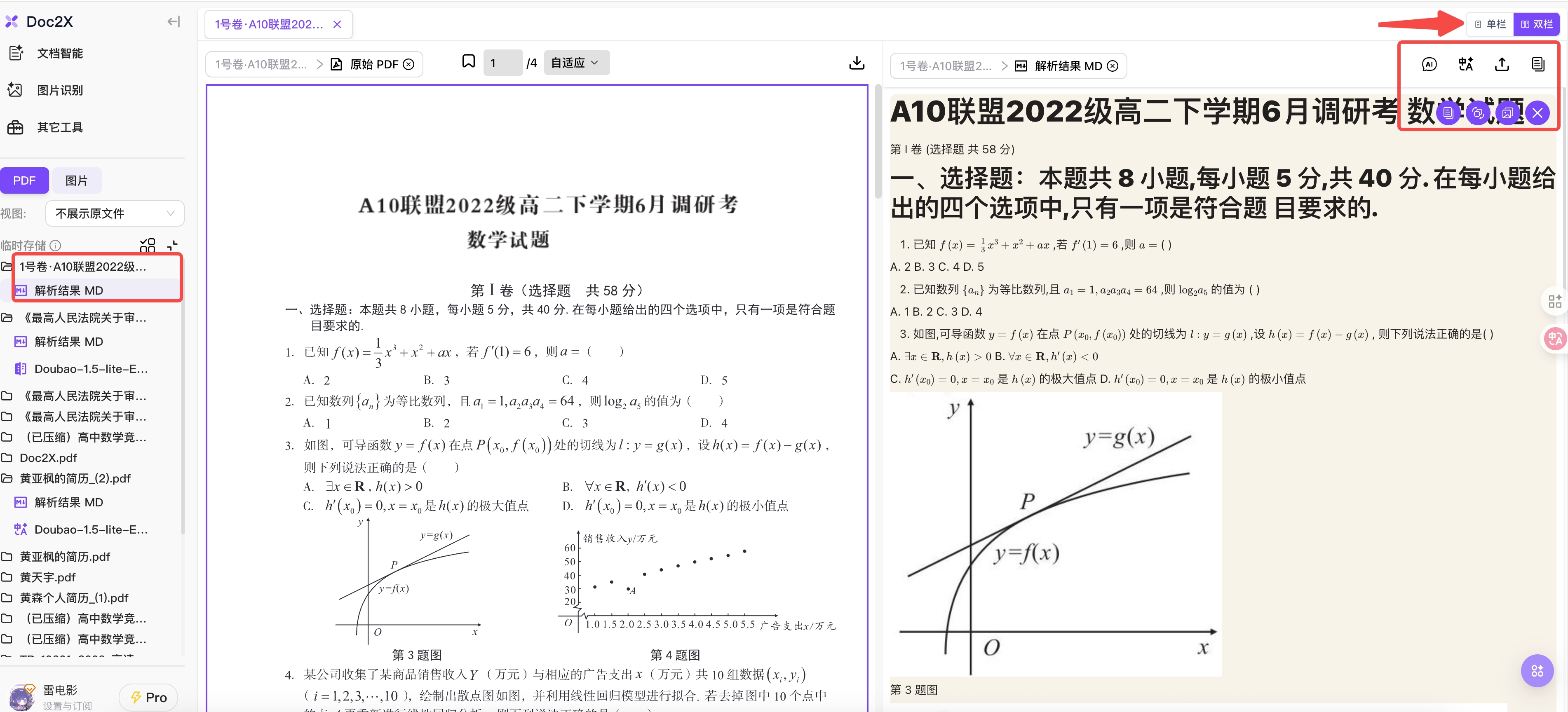
步骤 4:下载解析结果
- 点击"导出"图标,选择要保存的文件格式(Markdown、Word 等)
- 即可将解析结果保存到本地