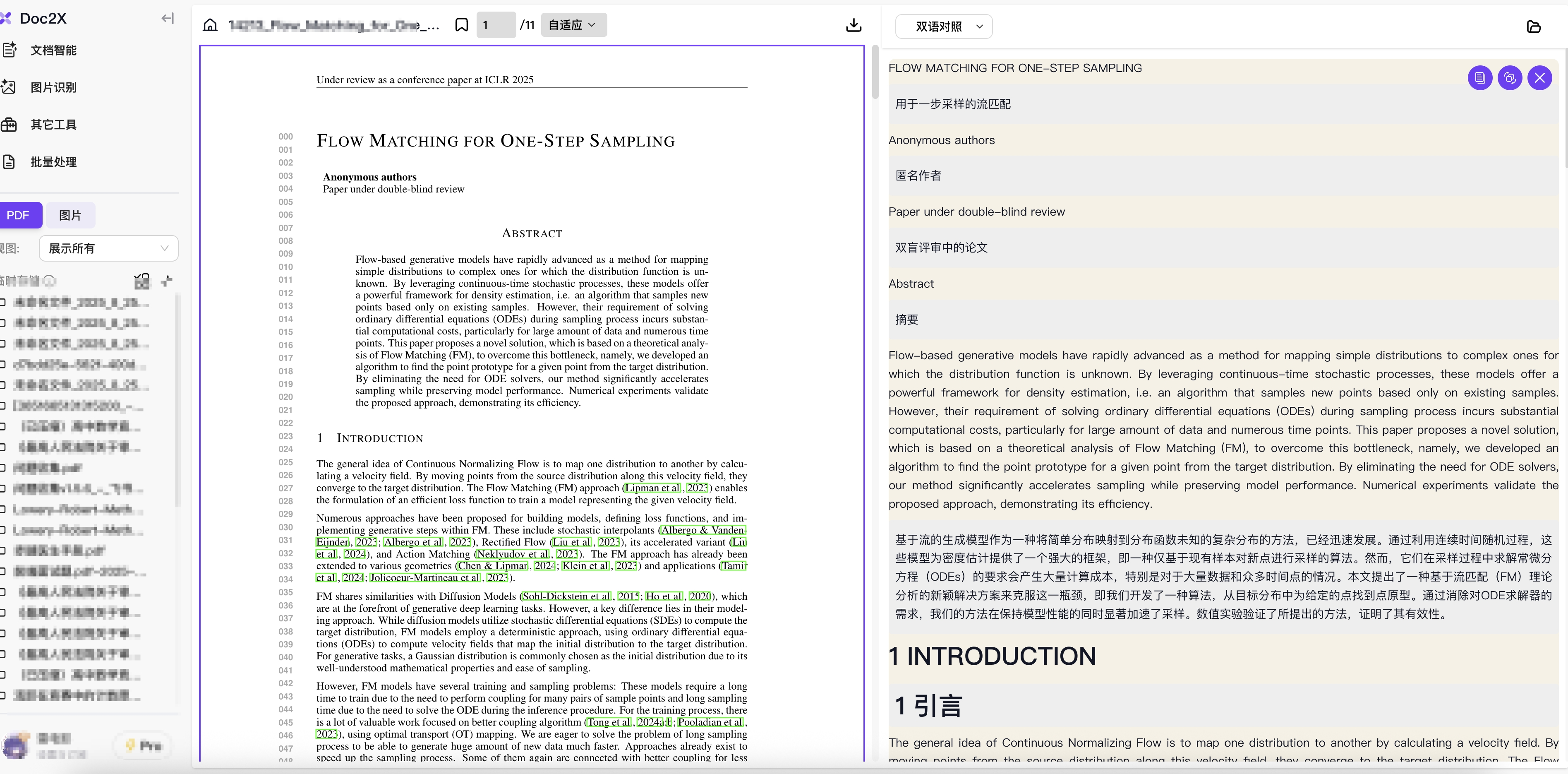
Doc2X C端批量处理系统
本文档介绍 Doc2X 客户端的批量处理功能和使用方法,帮助您高效处理大批量文档的解析和翻译任务。
系统介绍
Doc2X 在客户端版本新增了批量处理系统,实现了用户的大批量的文件解析/翻译,并将结果导出储存在本地
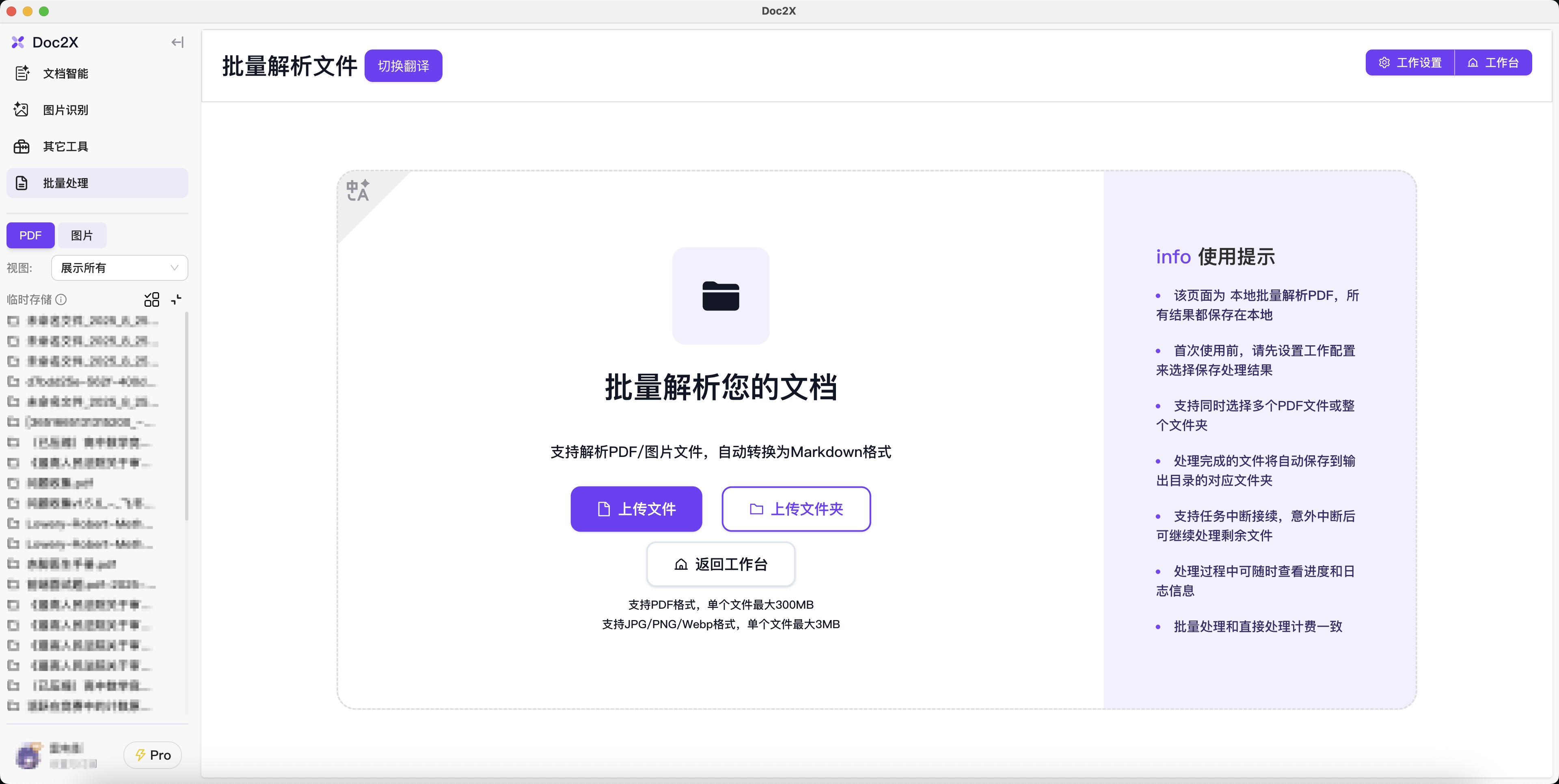
使用提示
- 首次使用前,请先设置工作配置来选择保存处理结果的目录。
- 支持同时选择多个PDF文件或整个文件夹。
- 处理完成的文件将自动保存到输出目录的对应文件夹中。
- 支持任务中断接续,意外中断后可继续处理剩余文件。
- 处理过程中可随时查看进度和日志信息。
- 批量处理和直接处理计费一致,解析默认自动应用当前折扣。
解析使用流程
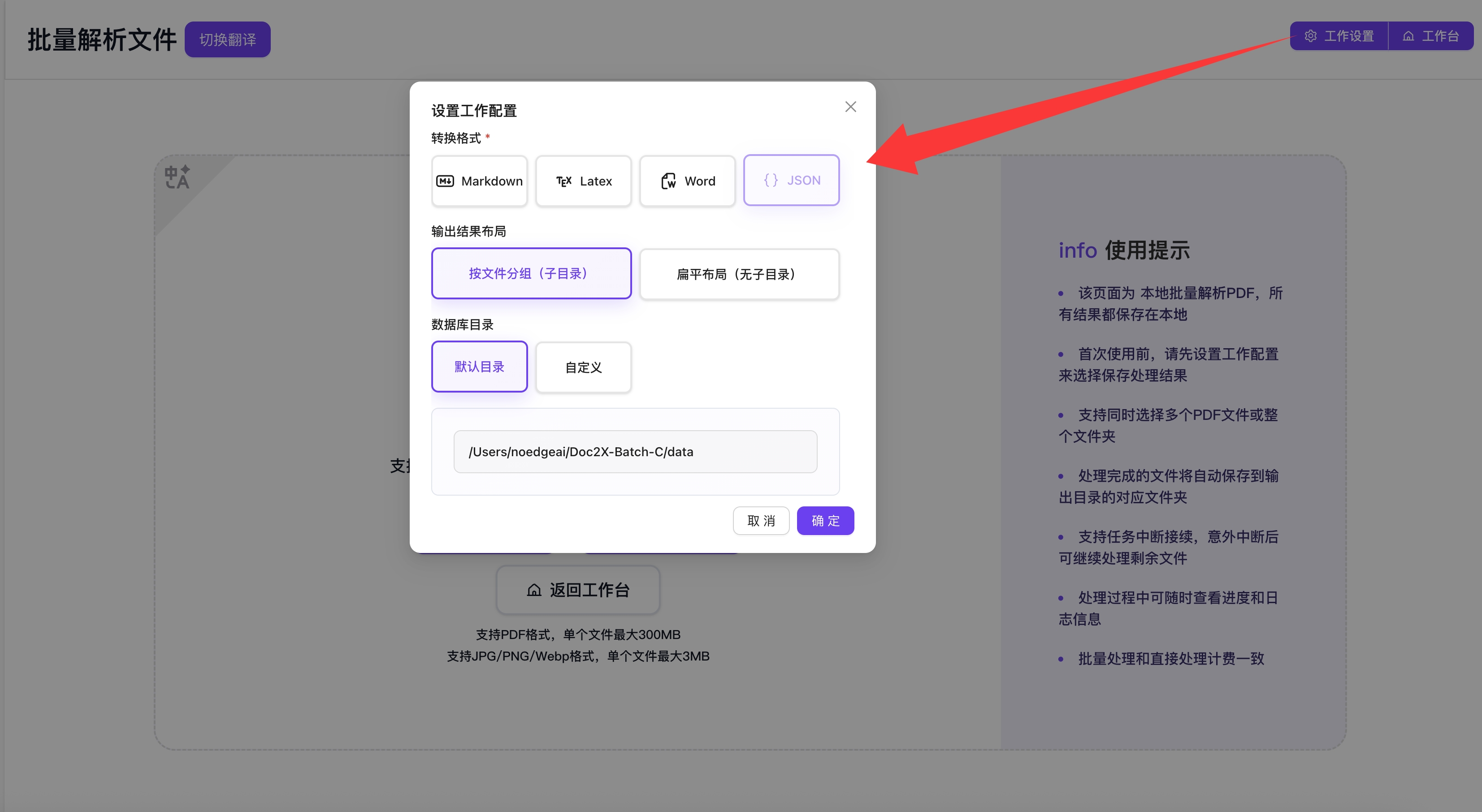
第一步:完成工作设置
在开始批量解析前,需要先配置以下设置:
转换格式(解析)
- 输出格式:选择导出格式(Markdown、Word、LaTeX、JSON 等)
输出结果布局(解析)
- 按文件分组:按照文件名将所有该文件相关导出放入一个子目录
- 扁平布局:无子目录,顺序导出
第二步:选择文件/文件夹
支持多种文件选择方式:
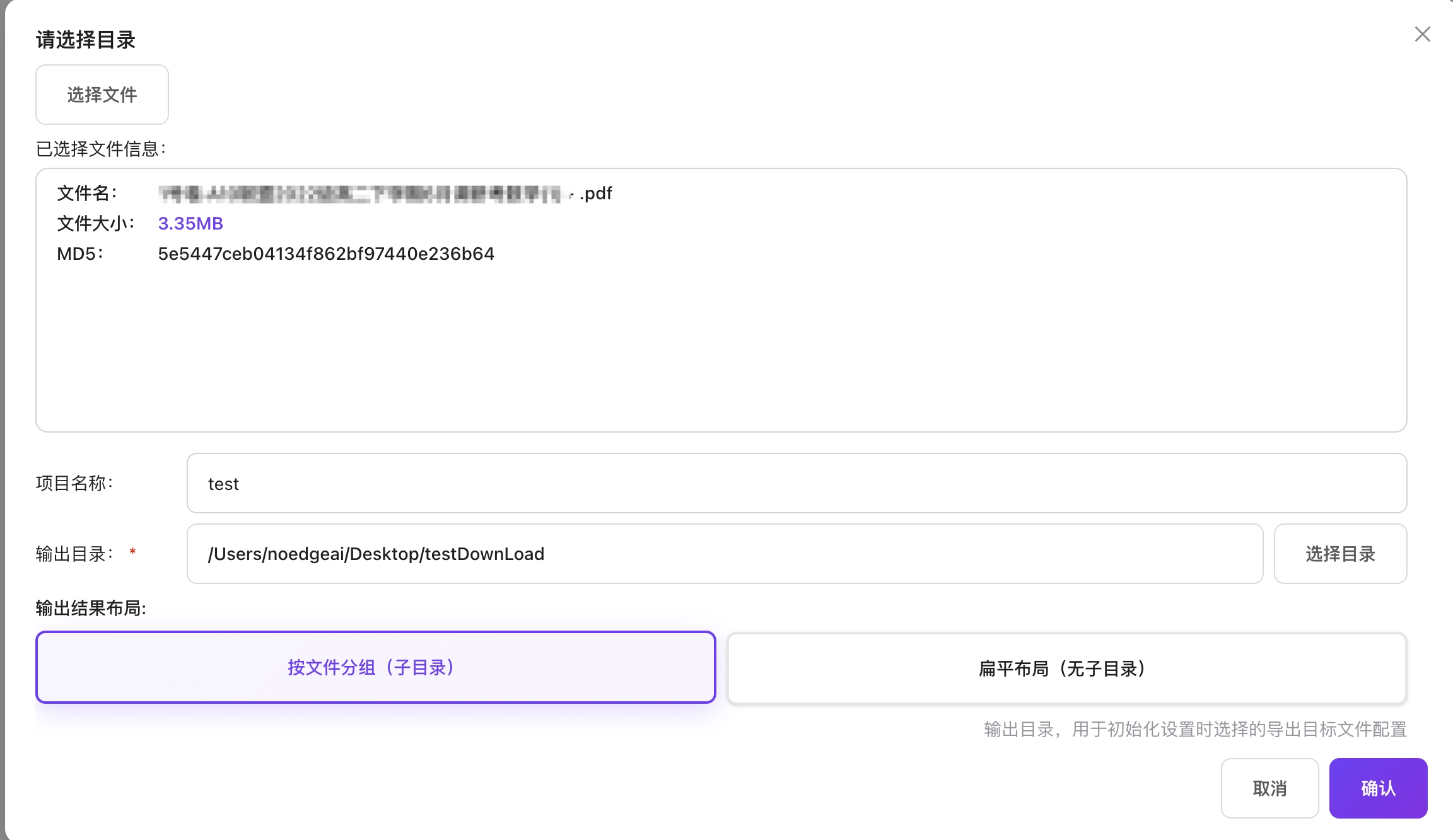
单文件选择(解析)
- 点击"上传文件"按钮
- 输入项目名称
- 选择输出目录
- 支持 PDF/图片格式
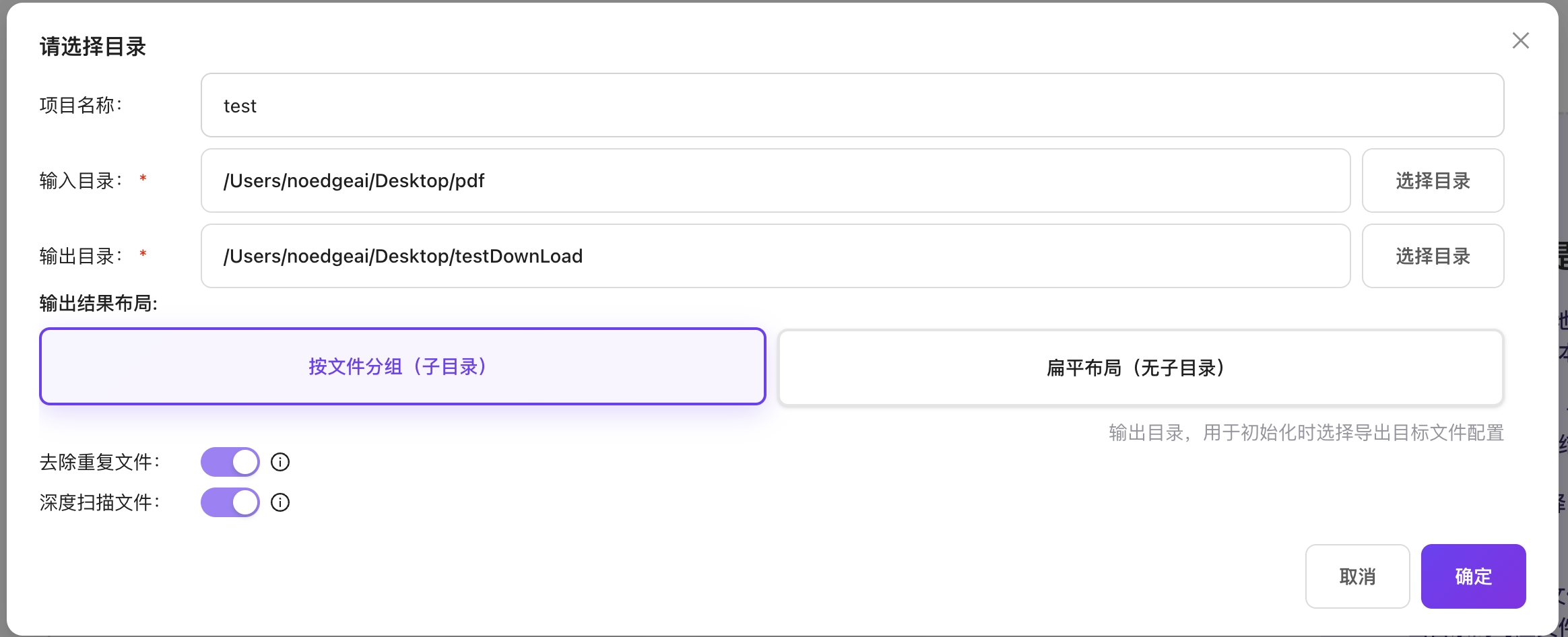
整个文件夹选择(解析)
- 选择"上传文件夹"选项
- 输入项目名称
- 选择输入目录
- 选择输出目录
- 可设置去除重复文件:会根据扫描文件md5对文件夹内md5值重复的文件进行去除。
- 可设置深度扫描文件:会递归扫描文件夹内所有子文件夹。
第三步:开始解析处理
- 点击"确认"按钮,系统会自动处理所有选中的文件/文件夹
- 可在工作台查看处理进度

第四步:查看解析结果
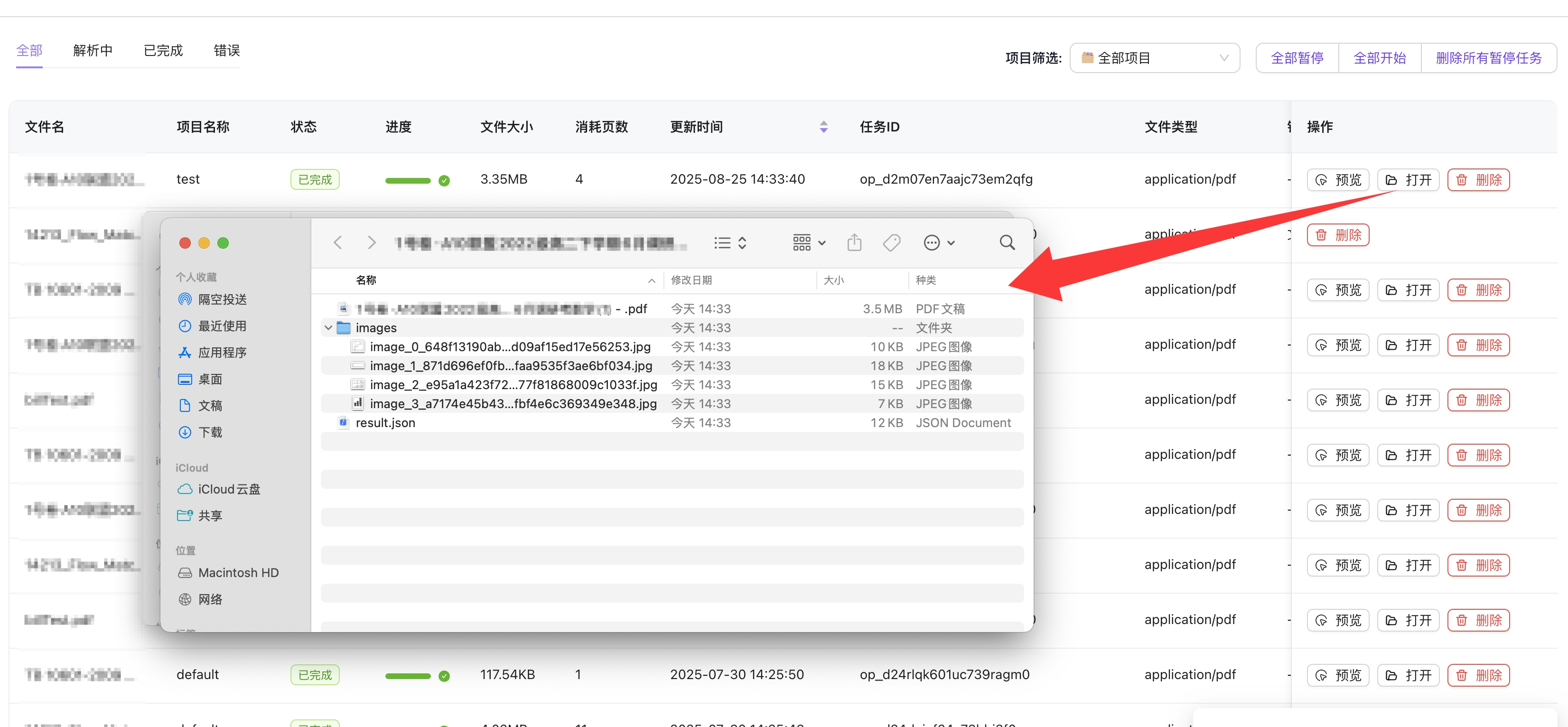
- 处理完成后,会在输出目录生成对应格式的文件/文件夹。
- 可以点击工作台表格右侧的"打开"按钮,查看导出结果。
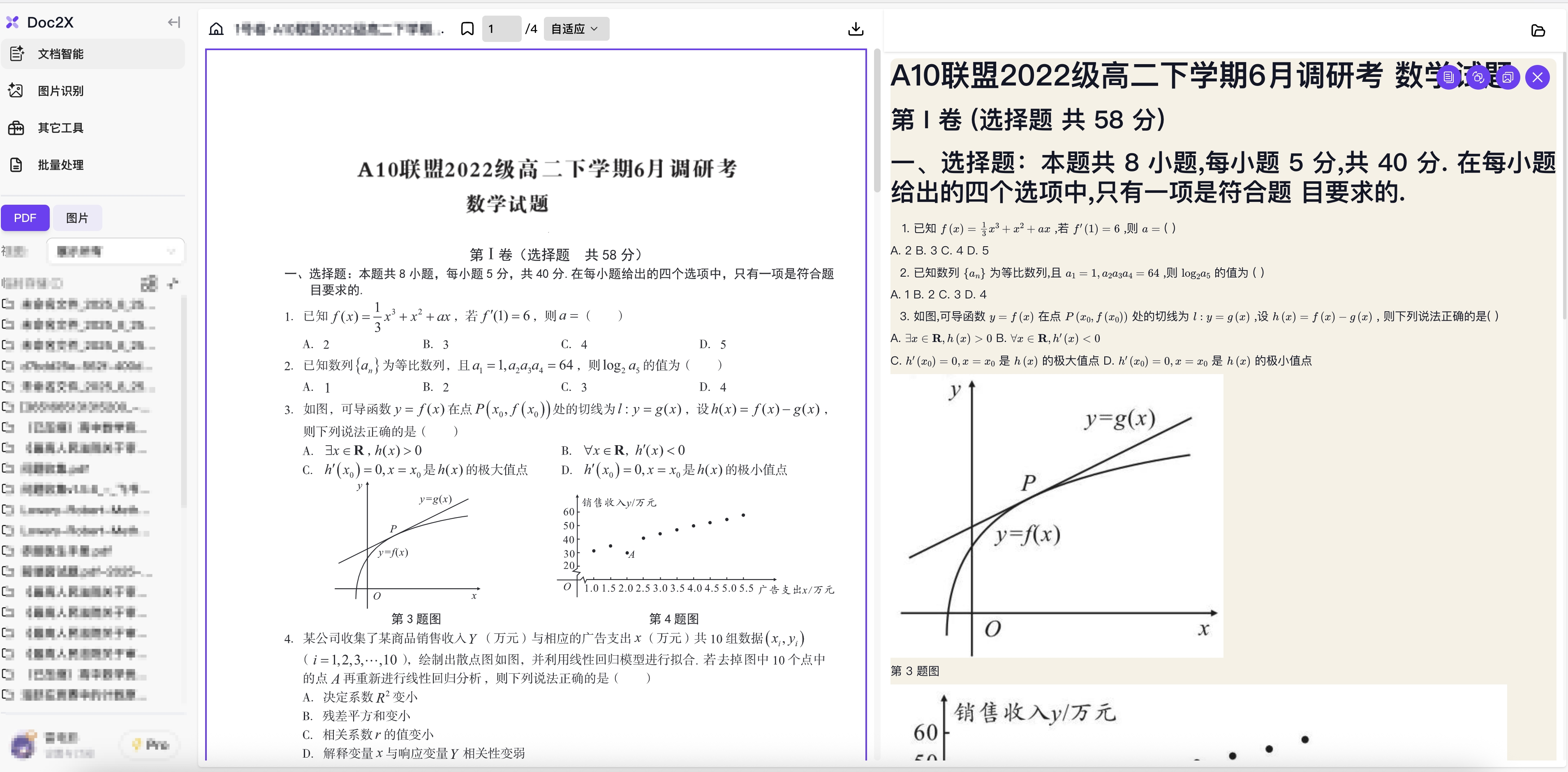
- 可以点击工作台表格右侧的"预览"按钮,跳转至预览界面。
翻译使用流程
第一步:完成翻译设置
在开始批量翻译前,需要先配置以下设置:
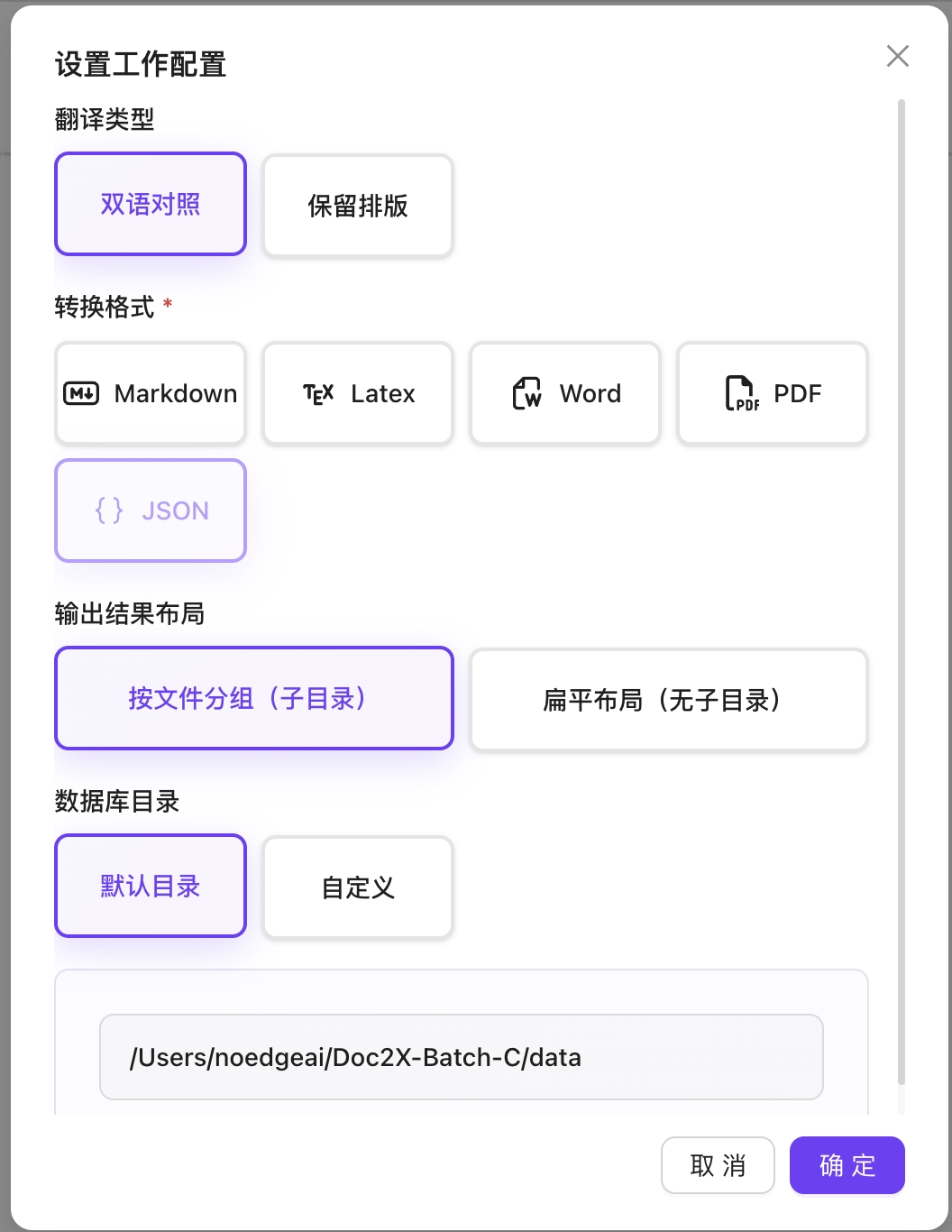
翻译类型
- 双语对照:双语对照翻译,会在翻译结果中保留原始文档的双语对照。
- 保留排版:保留原始文档的排版,不进行任何修改
转换格式(翻译)
- 输出格式:选择导出格式(Markdown、Word、LaTeX、JSON 等)
输出结果布局(翻译)
- 按文件分组:按照文件名将所有该文件相关导出放入一个子目录
- 扁平布局:无子目录,顺序导出
第二步:选择文件/文件夹
支持多种文件选择方式:
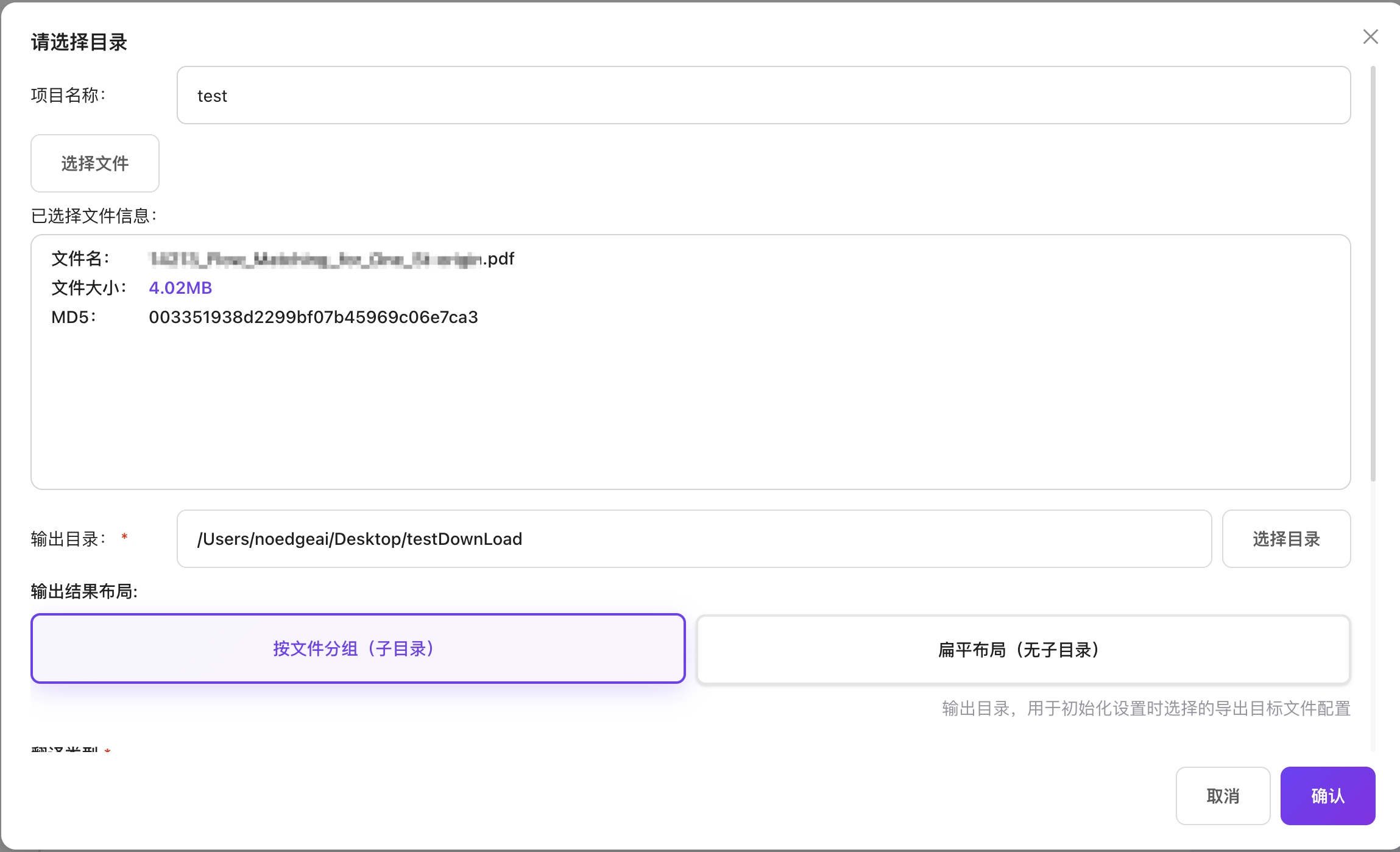
单文件选择(翻译)
- 点击"上传文件"按钮
- 输入项目名称
- 选择输出目录
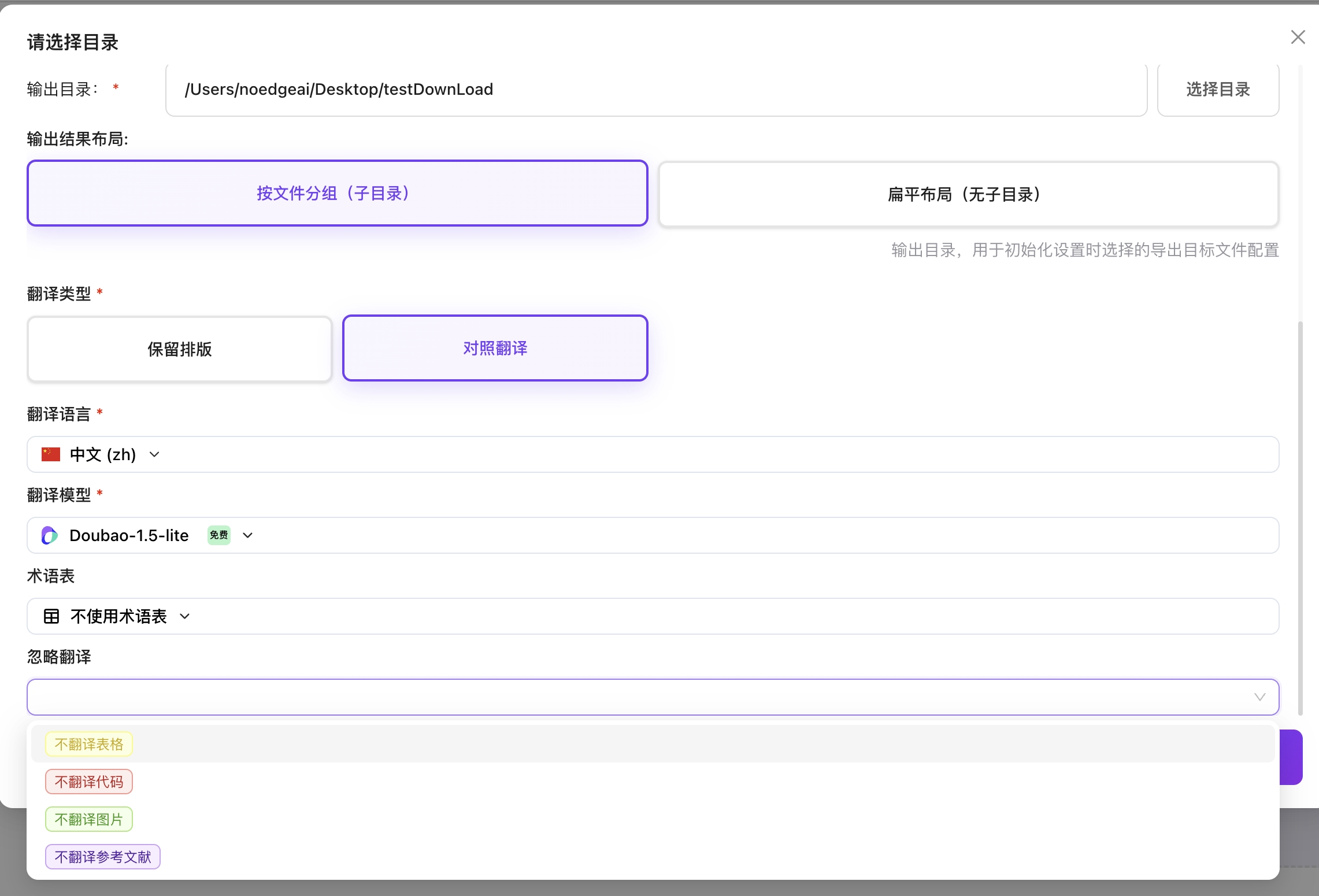
- 选择翻译类型(双语对照/保留排版)
- 选择翻译目标语言
- 选择翻译模型
- 选择术语表(可选)
- 选择忽略翻译(可选):可跳过表格/代码/文献等内容不翻译
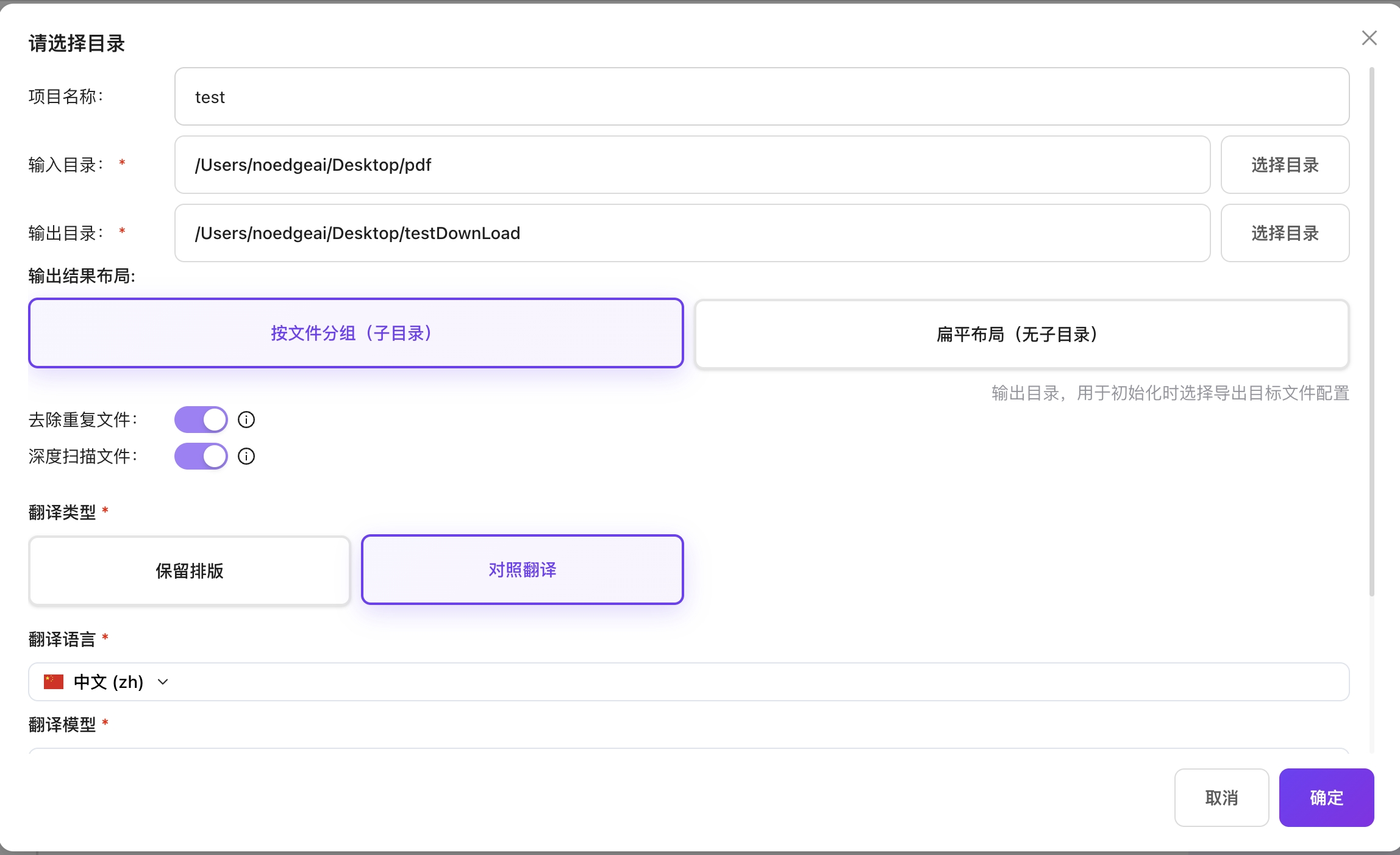
整个文件夹选择(翻译)
- 选择"上传文件夹"选项
- 输入项目名称
- 选择输入目录
- 选择输出目录
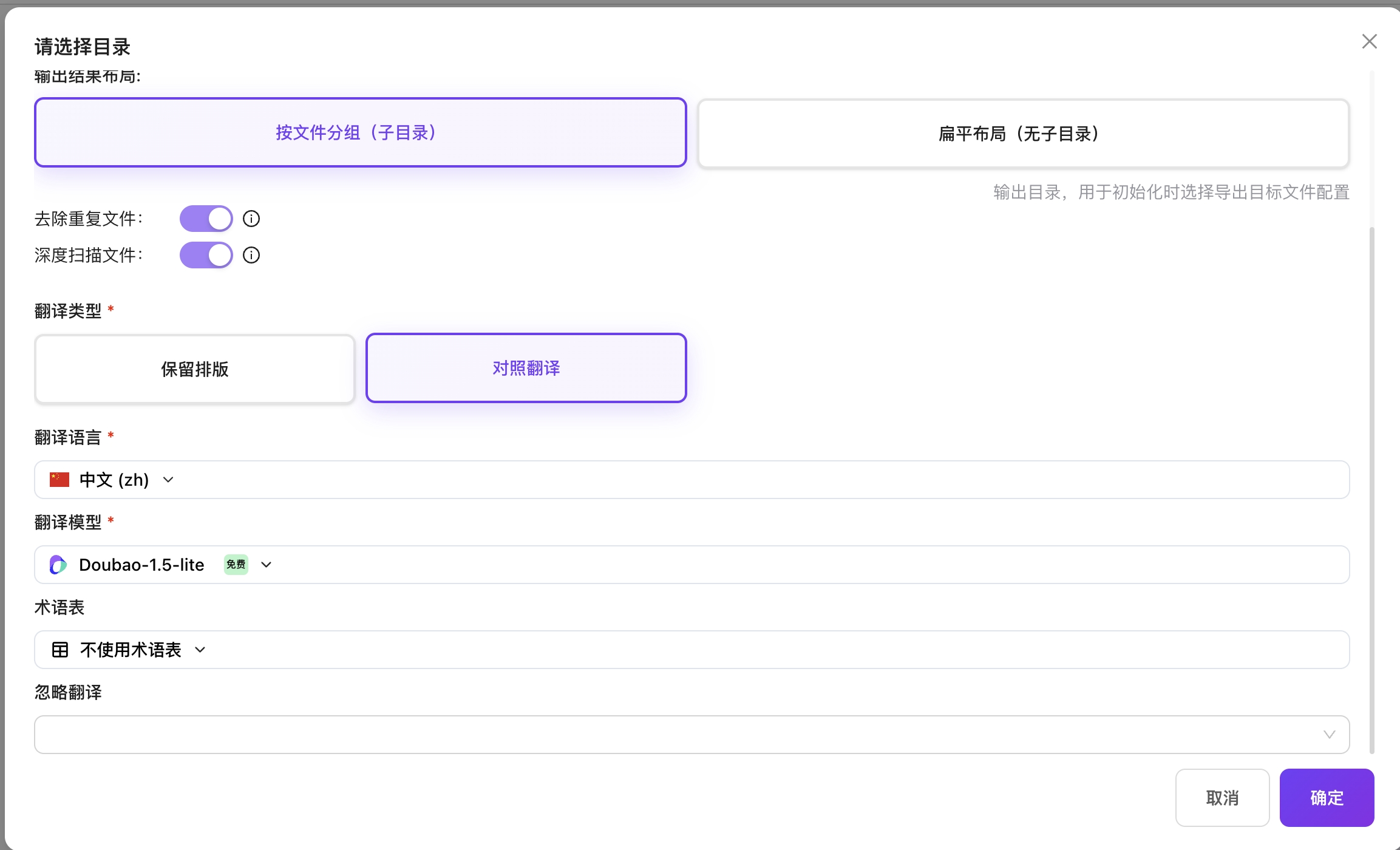
- 可设置去除重复文件:会根据扫描文件md5对文件夹内md5值重复的文件进行去除。
- 可设置深度扫描文件:会递归扫描文件夹内所有子文件夹。
- 选择翻译类型(双语对照/保留排版)
- 选择翻译目标语言
- 选择翻译模型
- 选择术语表(可选)
- 选择忽略翻译(可选):可跳过表格/代码/文献等内容不翻译
第三步:开始翻译处理
- 点击"确认"按钮,系统会自动处理所有选中的文件/文件夹
- 可在工作台查看翻译进度

第四步:查看翻译结果
- 处理完成后,会在输出目录生成对应格式的文件/文件夹。
- 可以点击工作台表格右侧的"打开"按钮,查看导出结果。
- 可以点击工作台表格右侧的"预览"按钮,跳转至预览界面。
![]()