
Doc2X 功能介绍
Doc2X 提供了 PDF 文档解析和文档翻译的一键解决方案
解析功能介绍
Doc2X 提供强大的 PDF 文档解析能力,支持将各种格式的 PDF 文档转换为结构化的文本格式。主要特点包括:
智能版面识别
自动识别文档中的标题、段落、表格、图片等元素

多格式输出
支持转换为 Markdown、Word、纯文本、LaTeX等多种格式
高精度解析
采用自研高精度的 OCR 技术,支持简繁中文、英文、日语、西欧各国语言(除俄语)等语言识别、准确率高达 99% 以上
- 复杂矩阵与线性代数公式的精确识别

- 手写笔记中的公式 OCR 识别展示:轻松转化为可编辑格式

- 复杂旋转表格正确识别
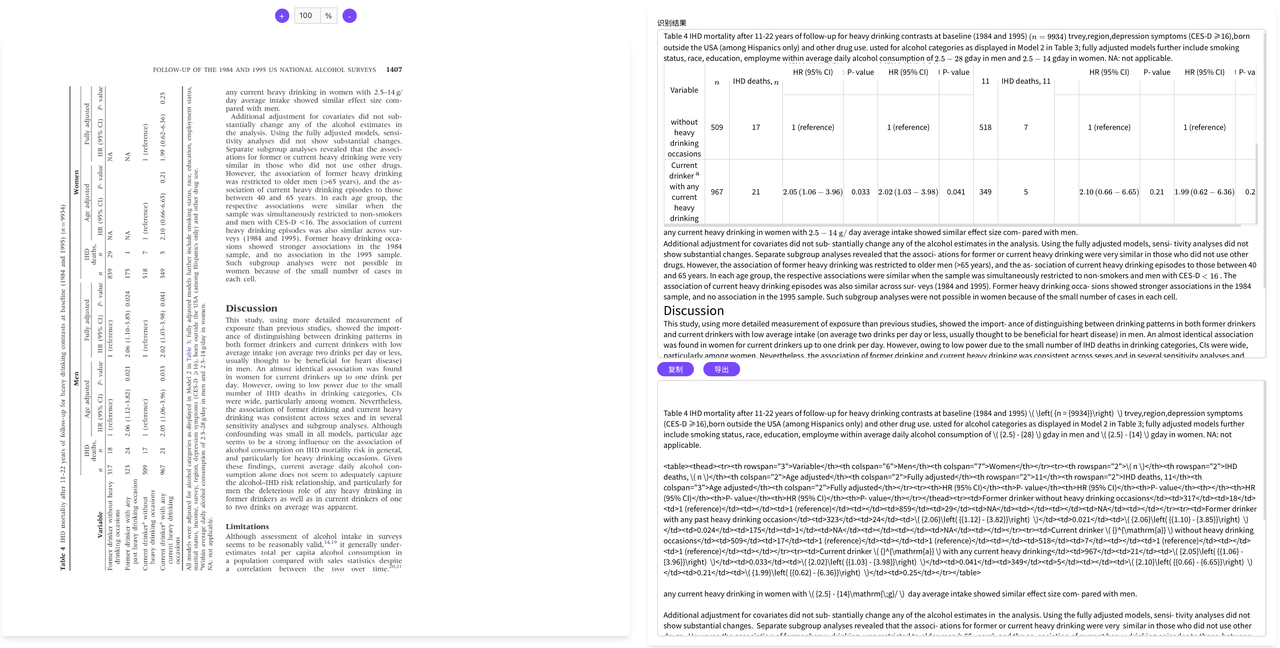
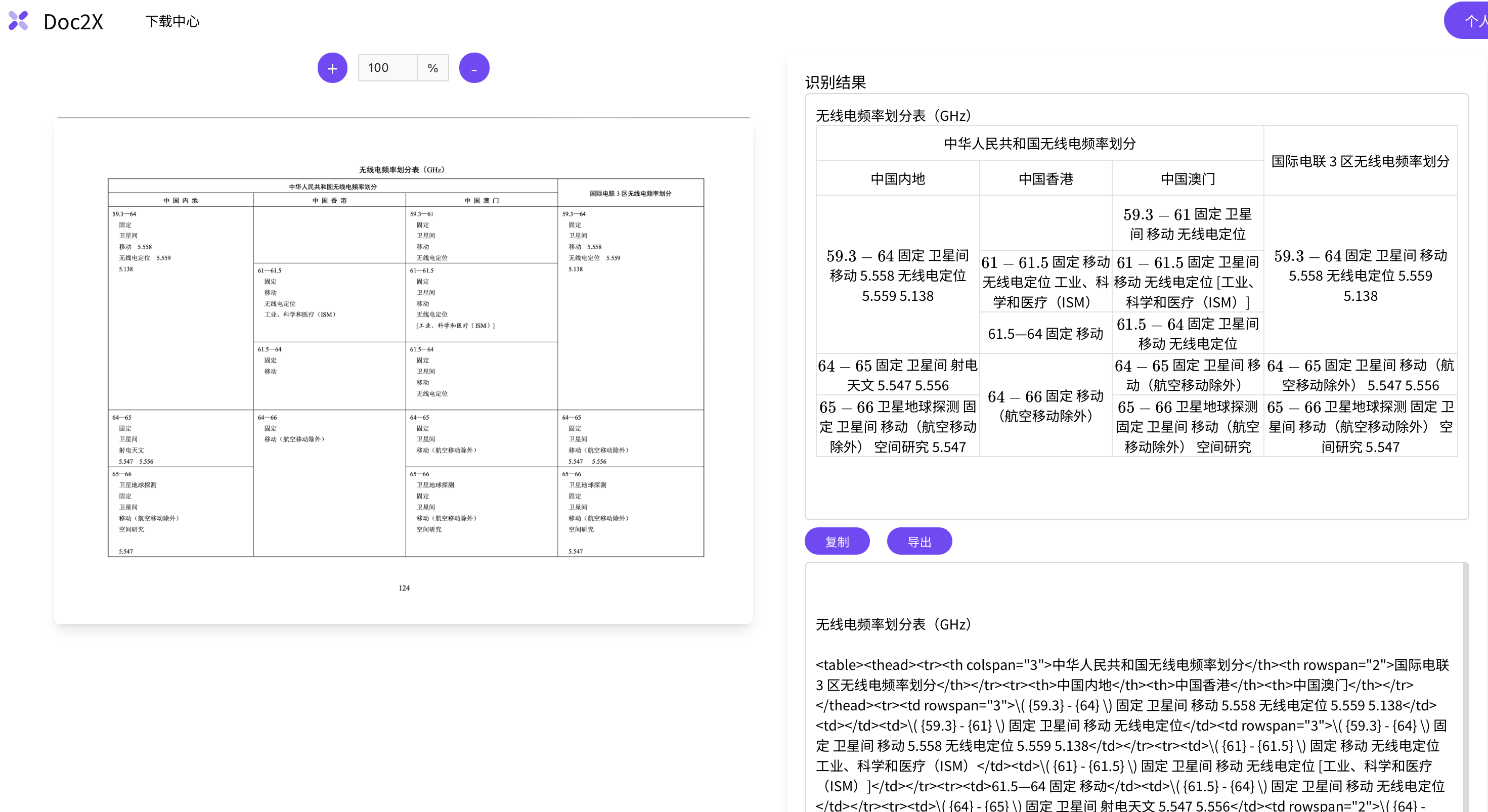
- 精确识别复杂合并单元格表格
批量处理
支持批量解析翻译多个 PDF 文档、大用量用户可以一键完成操作
翻译功能介绍
Doc2X 集成了专业的文档翻译功能,为用户提供高质量的多语言翻译服务:
多种大模型翻译引擎
集成 GPT、Gemini、Deepseek、Qwen、Doubao 等模型,对照输出多版本翻译结果,确保选择最优译文

双语对照与双向跳转
提供原文与译文并行展示,一键跳转查看对应段落,提升理解与校对效率
保留公式与布局格式
区别于谷歌翻译、微软翻译等传统机器翻译,Doc2X 在处理 PDF 时可还原公式、表格结构,支持翻译图片内部的文字、确保精准表达
适应专业术语与学术场景
针对学术论文、技术手册、研究报告与教育资料的专业术语翻译更准确,有助于跨语言学术交流
快速批量翻译
支持多页 PDF 及批量文档的快速翻译处理,大幅提升工作与学习效率
相关文档
- FAQ 常见问题 - 使用过程中的常见问题解答